What Are Embeddings in Machine Learning?
Embeddings in machine learning are techniques used to transform high-dimensional data into lower-dimensional vector spaces. This allows complex data such as words, images, or nodes in a graph to be represented as vectors of real numbers, known as embeddings.
Embeddings encapsulate the most relevant information about the data, making it easier for machine learning models to process and analyze. The aim is to preserve the semantic relationships present in the original data.
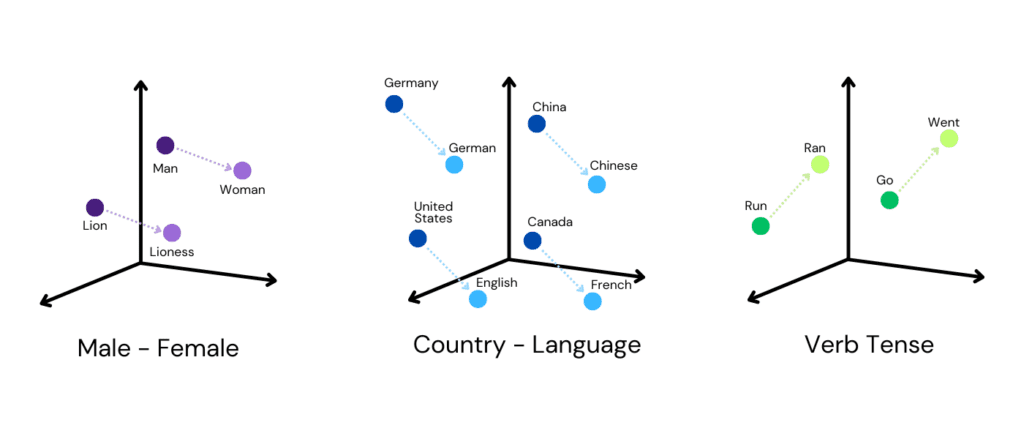
For example, in text data, words with similar meanings are represented by vectors that are close to each other in the embedding space. This property is crucial for many machine learning applications as it helps models generalize better and perform more efficiently on tasks like classification, clustering, and recommendation systems.
This is part of a series of articles about generative models.
In this article:
- Why Are Embeddings Important?
- What Are Vectors in Embeddings?
- How Do Embeddings Work?
- How Are Embeddings Used in LLMs?
- 4 Types of Embeddings in ML
- 4 Common Embedding Models
- Steps to Create Embeddings in Your ML Project
Why Are Embeddings Important?
Embeddings represent complex data like text, images, and graphs in a way that computers can understand—through vectors in a lower-dimensional space. These compact representations capture the essence of the data, preserving relationships and context without massive computing resources.
Embeddings can improve model performance, enabling tasks like recommendations, image recognition, and natural language processing. By representing similar items closer in vector space, they help machine learning algorithms efficiently process and analyze large datasets.
What Are Vectors in Embeddings?
Vectors are numerical representations of data points in a continuous space. Each vector typically has a fixed number of dimensions, which is significantly lower than the original data’s dimensionality. These vectors are derived using various embedding techniques and models that learn to encode the data’s essential features and relationships.
For example, in the case of word embeddings, each word in a vocabulary is mapped to a vector of real numbers. These vectors capture the syntactic and semantic properties of words based on their usage and context within a large corpus of text. For image embeddings, each image is converted into a vector that encapsulates its visual characteristics, such as shapes, textures, and colors, learned through deep learning models.
How Do Embeddings Work?
Embeddings operate by transforming raw data into continuous numerical values that machine learning (ML) models can interpret and learn from. This process involves vectorizing data points into a lower-dimensional space where the vectors capture the essential features and relationships within the data.
Embeddings begin by assigning a unique vector to each data point. These vectors are initially random but are adjusted during the training process to reflect meaningful patterns and similarities in the data. For example, in text data, words with similar meanings or that appear in similar contexts will end up with vectors that are close to each other in the embedding space.
The core of embeddings lies in their ability to reduce dimensionality. By converting high-dimensional data into a more compact form, embeddings make it possible to preserve significant information while reducing the computational complexity. This dimensionality reduction is achieved through neural networks or other algorithms that learn to map data into a lower-dimensional space.
Through training, embeddings learn to position data points in the vector space so that the geometric relationships between vectors reflect the relationships between the original data points. For instance, in word embeddings, words with similar syntactic or semantic properties will have vectors that are close together. This proximity in the vector space allows ML models to better capture and utilize the underlying structure and patterns in the data.
How Are Embeddings Used in LLMs?
Large Language Models (LLMs) are rapidly growing in popularity and are enabling applications like automated content generation, intelligent chatbots, and coding assistance. Embeddings are a critical foundation of LLMs; they allow language models to represent and process the vast amounts of text data they are trained on.
Here are some of the ways that embeddings enable LLMs to learn:
- Contextual representation: Embeddings in LLMs capture the context of words in sentences. Unlike traditional word embeddings, LLMs use contextual embeddings where the representation of a word depends on its surrounding words. This allows the model to understand nuanced meanings and disambiguate words based on context.
- Tokenization and embedding layer: When processing text, LLMs first tokenize the input into smaller units (tokens), which are then converted into vectors using an embedding layer. This layer maps each token to a high-dimensional vector that encodes semantic information. For example, in models like BERT (Bidirectional Encoder Representations from Transformers), each token is represented by a vector that considers both left and right context.
- Transfer learning: Pre-trained LLMs, such as GPT-4, Gemini and BERT, use embeddings to transfer learned knowledge to various downstream tasks. The embeddings from these models serve as a source of information that can be fine-tuned on tasks such as text classification, question answering, and named entity recognition.
- Attention mechanisms: In transformer-based architectures, embeddings are essential for the attention mechanisms that allow the model to weigh the importance of different tokens in a sequence. This helps the model focus on relevant parts of the input when generating predictions, enhancing its ability to understand and generate coherent text.
- Handling out-of-vocabulary words: Embeddings can also manage out-of-vocabulary (OOV) words through subword tokenization techniques like Byte Pair Encoding (BPE) or SentencePiece. By breaking down words into smaller units, LLMs can generate embeddings for previously unseen words.
4 Types of Embeddings in ML
Embeddings can be used to represent different types of data in machine learning.
1. Image Embeddings
Image embeddings convert visual information into a vector form by processing features like texture, edges, and color gradients through deep learning models. These embeddings are useful in applications such as facial recognition, image classification, and automated image captioning.
They convert complex visual inputs to a form that ML models can easily manipulate. This transformation allows for more accurate comparisons and classifications of new images against a trained dataset.
2. Word Embeddings
Word embeddings are common in natural language processing, used to map words or phrases from the vocabulary to vectors of real numbers. They capture the semantic and syntactic similarities between words based on their co-occurrence in large text corpora.
Models like Word2Vec or GloVe are often used to generate word embeddings. The resulting vector representations help in tasks such as text analysis, sentiment analysis, and machine translation, which require understanding context and word relationships.
3. Graph Embeddings
Graph embeddings convert nodes, edges, and their attributes into a low-dimensional space while preserving properties like node connectivity and graph topology. This is useful for analyzing social networks, biochemical structures, or any system that can be represented as a graph.
These embeddings enable tasks such as link prediction, community detection, and anomaly detection within graphs. By simplifying the complex relationships in graph data into a manageable form, ML models can more effectively process and infer from the data.
4. Entity Embeddings
Entity embeddings represent objects and their relationships within a dataset, making them useful in recommender systems and relational databases. These embeddings are learned in a way that similar entities have closely situated vectors.
This technique enables systems to make better recommendations based on user-item interactions and other relational metrics. It can be used for improving personalized experiences and services.
4 Common Embedding Models
1. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a linear dimensionality reduction technique used to reduce the number of features in a dataset while preserving as much variance as possible. PCA transforms the original data into a new set of orthogonal components, ordered by the amount of variance they capture. It is widely used in exploratory data analysis and for reducing the dimensionality of data before applying machine learning algorithms.
Key features:
- Data standardization: Standardize the dataset so that each feature has a mean of zero and a standard deviation of one.
- Covariance matrix: Compute the covariance matrix to understand the relationships between different features.
- Eigenvalues and eigenvectors: Calculate the eigenvalues and eigenvectors of the covariance matrix. The eigenvectors determine the directions of the new feature space, while the eigenvalues indicate the magnitude of variance along those directions.
- Transform data: Project the original data onto the new feature space defined by the top eigenvectors (principal components).
2. SVD
Singular Value Decomposition (SVD) is a technique for reducing the dimensionality of data by decomposing it into three components. It captures the most important features of the original data in a compact form. SVD is particularly useful in natural language processing for tasks like latent semantic analysis, where it helps uncover hidden relationships and structures in text data.
Key features:
- Matrix decomposition: SVD breaks down the data matrix into three separate matrices. This decomposition helps to reveal the underlying structure of the data.
- Dimensionality reduction: By focusing on the most significant components identified during decomposition, SVD reduces the data to fewer dimensions while retaining most of the essential information.
3. Word2Vec
Word2Vec is a word embedding technique developed by Google that maps words to continuous vector spaces using shallow neural networks. Its embeddings capture semantic similarities between words, making them useful for various NLP tasks.
Key features:
- Training models: There are two main architectures for training Word2Vec models: Continuous Bag of Words (CBOW) and Skip-gram. CBOW predicts the target word from its context, while Skip-gram predicts the context words from the target word.
- Context window: Define a context window around each word to determine the surrounding words used for predictions.
- Optimization: Train the model using techniques like negative sampling or hierarchical softmax to optimize the word vectors.
4. BERT
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based model that generates contextualized word embeddings. BERT’s embeddings are effective for a range of NLP tasks due to their deep contextual understanding of language.
Key features:
- Bidirectional training: Unlike traditional models that process text in a unidirectional manner, BERT processes text bidirectionally, considering both left and right contexts simultaneously.
- Pre-training tasks: BERT is pre-trained on two tasks: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). MLM involves predicting masked words in a sentence, while NSP involves predicting whether two sentences follow each other in a text.
- Fine-tuning: After pre-training, BERT can be fine-tuned on specific tasks by adding task-specific layers on top of the pre-trained model and training on labeled data.
Steps to Create Embeddings in Your ML Project
Here’s an overview of the process of creating embeddings for machine learning applications.
Choose or Train an Embedding Model
The choice of an embedding model largely depends on the task and the nature of the data. Different models are optimized for different types of data—text, images, or structured data. A pre-trained model may be preferred for its convenience and broad applicability, while training a new model might be the best way to capture domain-specific nuances.
If training a model, the key considerations include the selection of model architecture, the size of the training corpus, and the computational resources available. These factors significantly influence the effectiveness of the resulting embeddings.
Prepare Custom Data or Load a Pre-Trained Embedding Model
There are generally two options when generating embeddings: working with your own custom data or using a pre-trained model.
Working with custom data
In this case, you will need to prepare data, which involves cleaning it, selecting relevant features, and sometimes transforming raw data into a format that the embedding model can process. For text data, this might mean tokenizing text into words or sentences, and for image data, applying various image preprocessing techniques.
The integrity and quality of input data directly affect the quality of the embeddings. Thorough data preparation helps ensure more accurate, meaningful embeddings, which in turn support more powerful machine learning models.
Working with pre-trained models
Alternatively, you can load a pre-trained embedding model. Loading pre-trained models saves time and computational resources and provides access to high-quality embeddings developed on extensive, diverse datasets. Make sure the pre-trained model is appropriate to your use case and its training data is similar to the data you expect your model to encounter.
Generate Embeddings
Once the model is ready, it can start generating embeddings. This process involves feeding the prepared data into the embedding model and extracting the vector representations. These vectors should accurately reflect the characteristics and relationships inherent in the original data.
Ensuring that the embeddings are meaningful and useful requires evaluating and possibly refining them based on their performance in the intended tasks or their alignment with expected data properties.
Integrate the Embeddings into the Application
The final step is to integrate the generated embeddings into the target machine learning application. This could mean using the embeddings as input features for ML models, in similarity analyses, or for direct data exploration and visualization.
Integrating embeddings can improve the application’s performance, enable new functionalities, and drive insights that were previously difficult to obtain due to the complexity or sheer size of the raw data.
AI Testing & Validation with Kolena
Kolena is an AI/ML testing & validation platform that solves one of AI’s biggest problems: the lack of trust in model effectiveness. The use cases for AI are enormous, but AI lacks trust from both builders and the public. It is our responsibility to build that trust with full transparency and explainability of ML model performance, not just from a high-level aggregate ‘accuracy’ number, but from rigorous testing and evaluation at scenario levels.
With Kolena, machine learning engineers and data scientists can uncover hidden machine learning model behaviors, easily identify gaps in the test data coverage, and truly learn where and why a model is underperforming, all in minutes not weeks. Kolena’s AI / ML model testing and validation solution helps developers build safe, reliable, and fair systems by allowing companies to instantly stitch together razor-sharp test cases from their data sets, enabling them to scrutinize AI/ML models in the precise scenarios those models will be unleashed upon the real world. Kolena platform transforms the current nature of AI development from experimental into an engineering discipline that can be trusted and automated.