
Solution
LLM and AI Agent Quality
Automate data enrichment and model quality evaluation processes with unstructured text data when using the latest LLMs for open-ended tasks, including agentic AI.

Compatible with all LLM-related tasks
Composed of building blocks for modeling your data, hydrating with metadata, and computing metrics, Kolena supports your tasks and can be customized to fit the specifics of your problem.
How it Works
Enrich and explore your language data. Rigorously evaluate model performance on any task. Automate your quality processes regardless of if you're going from 0→1 or 1→100.
01Enrich
Leverage state-of-the-art LLMs, embedding extractors, toxicity classifiers PII detectors, and zero-shot classification and entity extraction models to add domain-specific metadata to your datapoints.
02Explore
Minimize the distance between you and your data. Navigate and visualize chat traces, PDF documents, diff, and extracted entities in the Studio to dig deeper than metrics and perform root-cause analysis.
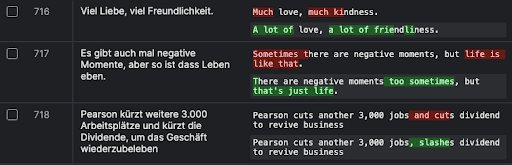
03Evaluate
Leverage scenario-based evaluation using traditional metrics, model-assisted metrics (LLM judge), and human metrics to pinpoint failures and catch regressions before deployment.
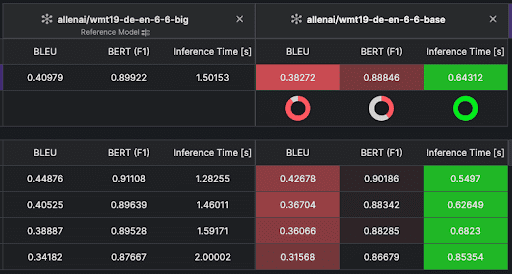
04Export
Plug evaluations into CI/CD pipelines to automatically approve or reject changes. Export enriched datasets for training, testing, or further analysis.
Key Features
Automated metadata extraction
Integrate with state-of-the-art models for metadata hydration
- Zero-shot NER
- Zero-shot classification
- Toxicity rating
- PII detection
- Embeddings-based classification
- LLM-powered extraction
- Zero-shot NER
- Zero-shot classification
- Toxicity rating
- PII detection
- Embeddings-based classification
- LLM-powered extraction
Chat, PDF, code visualization
Text data is more than just snippets
- Log chat traces from your favorite tools like LangChain or LlamaIndex
- Connect PDFs, Markdown files, HTML files
- Log chat traces from your favorite tools like LangChain or LlamaIndex
- Connect PDFs, Markdown files, HTML files
Diff comparison
Inline and multiline
Human evaluation
- Supplement automated metrics with human evaluation using your own raters or Kolena-provided raters.
- Customize evaluation methodology and metrics collected.
- Save effort through statistical
- Customize evaluation methodology and metrics collected.
- Save effort through statistical
Comparing models made efficient, repeatable and inexpensive
-
Faster go to market50%Save up to 50% of experimentation time
-
Model DebuggingFasterDiscover failure root cause in minutes not weeks
-
Model Robustness30%Up to 30% gains on model performance


