What Is a Transformer Model?
A transformer model is an advanced machine learning model used to handle sequential data, like text or time series data. Unlike previous models that process data sequentially, transformers use mechanisms like attention to weigh the importance of different words or features, regardless of their position in the sequence. This allows for parallel processing of data, which is especially useful in tasks like translation and text summarization.
Originally proposed in the paper “Attention is All You Need” (Vaswani et al., 2017), transformers have set new benchmarks in natural language processing (NLP). This approach has given rise to popular language models like BERT, T5, and most recently, large language models (LLMs) like OpenAI GPT, Google Gemini, and Meta LLaMA.
What Is RNN?
A Recurrent Neural Network (RNN) is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence. This structure gives RNNs temporal dynamic behavior, making them suitable for tasks such as speech recognition, language modeling, and text generation.
Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs, which makes them powerful for sequential data analysis. RNNs can connect previous information to the present task. However, they often suffer from problems like vanishing or exploding gradients, which can make training over longer sequences challenging.
Advances such as LSTM (Long Short-Term Memory) or GRU (Gated Recurrent Units) models have addressed these issues to some extent, refining the utility and performance of RNNs in practical applications.
This is part of a series of articles about generative models
How Transformer Models Work
Transformers operate through a mechanism called self-attention, which quantifies the relevance of all parts of the input data to each other. These parts, such as words in a sentence or features in a data set, are compared to each other, and this comparison determines the output of the transformer at each step. This allows transformers to handle long-range dependencies and maintain context across the input sequence.
In addition to self-attention, transformers use positional encoding to maintain the order of the input data. The model processes data in parallel rather than sequentially, and positional encodings add unique information to each input component, helping the model understand the sequence order. Additional layers of multi-head attention and feed-forward neural networks are stacked together to form the encoder and decoder architecture.
How RNNs Work
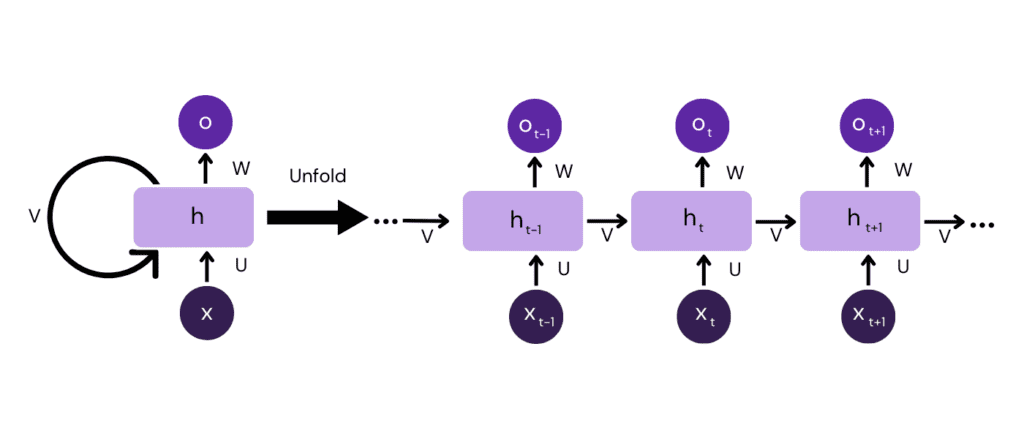
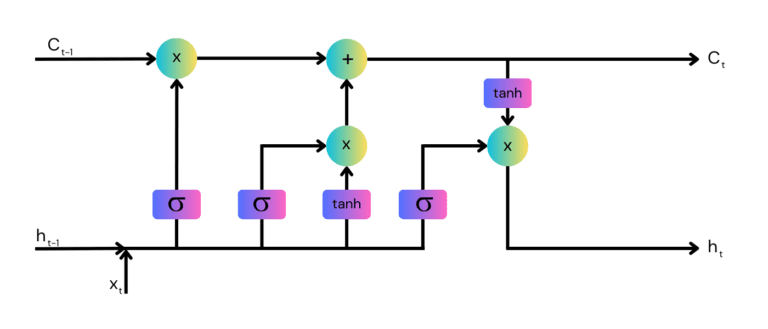
RNNs rely on the use of loops within a neural network. When an RNN processes a piece of input data, it combines this new data with its previously generated output, remembering information about the past. This loop within the architecture allows information to persist as it moves through the layers of the network. Each output from an RNN depends on both the current input and on a stepwise memory about all previous inputs.
RNNs typically have a simple structure with a single layer for input, hidden, and output states. This simple setup leads to both their capability and limitation—the network struggles to remember information for long periods due to issues like the vanishing gradient problem.
This problem occurs during training. Gradients are calculated by the backpropagation algorithm, which is used for updating network weights. These gradients become extremely small, stopping the network from learning further.
Transformer vs RNN: Key Differences
Let’s see how these two models differ in key areas.
1. Processing
Transformers use parallel processing to speed up their training and inference times compared to RNNs. By handling all parts of the input data simultaneously, transformers avoid the sequential processing bottleneck inherent in RNNs. This makes transformers particularly well-suited for environments that can support large-scale parallel computational power.
RNNs process data sequentially. This sequential processing is essential for capturing temporal dynamics but becomes a limiting factor when scaling to longer sequences or larger datasets. The time it takes to process each step sequentially accumulates, leading to slower overall performance.
2. Memory and Dependencies
Transformers handle dependencies and memory through an attention mechanism that weights the importance of different parts of the input data. This allows them to maintain long-range dependencies, mitigating issues like the vanishing gradient problem seen in RNNs. The attention model provides a context for any position in the input sequence.
RNNs, while theoretically capable of handling long-term dependencies through their recursive nature, often fail in practice unless supplemented with mechanisms like LSTM or GRU. These mechanisms help maintain a more stable memory state over longer sequences, but they still cannot match the efficiency of the transformer’s attention mechanism.
3. Scalability
Transformers scale well with increased data and computational resources. This scalability is visible in large-scale NLP models like GPT-3 and GPT-4, which can perform a wide variety of tasks with minimal task-specific training due to their large training corpora and model capacity.
RNNs face significant challenges in scaling. The sequential nature of the model inherently restricts its ability to parallelize computations, leading to higher training times and increased computational resources as model size and datasets grow. Even with optimization techniques, RNNs cannot match transformers in handling large-scale tasks.
4. Applications
Transformers are predominantly used in tasks that benefit from understanding the entire context of the input data, such as full-text translation, summarization, and multi-task learning. The model’s ability to evaluate all parts of the input data simultaneously allows it to perform well in complex NLP tasks.
RNNs find their niche in applications that require fine-grained temporal dynamics. These include speech recognition, where the temporal sequence of sounds plays a significant role, or in generative tasks where the sequence of generated elements is heavily dependent on the immediate past.
RNN vs Transformer: How to Choose?
In general, the transformer architecture is today the state of the art in NLP and RNN is considered obsolete for many use cases. However, for some projects RNN can still be relevant. Here are some of the main factors to consider when making this choice:
- The type of the task: RNNs are often preferable for tasks where the sequence order and fine-grained temporal dynamics are essential, such as speech recognition and time-series prediction. Transformers are better for tasks requiring a comprehensive understanding of the entire input context, like text translation, summarization, and question answering.
- Data characteristics: Transformers require large datasets to realize their full potential due to their extensive parameterization. If the dataset is extensive and diverse, a transformer model can leverage this to produce more accurate results. RNNs can perform well on smaller datasets where the sequential order is important.
- Availability of computational resources: Transformers, with their parallel processing capabilities, are well-suited for environments with ample computational power, such as GPUs or TPUs, enabling faster training and inference. However, they also demand more memory and computational resources. In contrast, RNNs, particularly simpler versions, can be more resource-efficient and may be preferable in resource-constrained environments.
- Model complexity and training time: Transformer models are generally more complex and require longer training times due to their larger architectures and extensive parameter sets. If quick deployment and shorter training times are critical, and if the task allows for it, RNNs might be a more practical choice.
- Handling long-range dependencies: Transformers are usually better for applications needing to capture long-range dependencies within the input data. RNNs, even with LSTM or GRU units, may struggle with very long sequences due to issues like the vanishing gradient problem.
- Adaptability to future tasks: Transformers offer greater flexibility for multi-task learning and transfer learning. Models like GPT and BERT can be fine-tuned for various downstream tasks with minimal task-specific training, making them versatile for evolving needs. RNNs often require more significant modifications and training to switch between different tasks.
- Industry Adoption and Community Support: Transformers are currently leading in research and applications within NLP and have extensive support from the community, including pre-trained models and extensive documentation. RNNs will not receive the same level of ongoing development and support.
AI Testing & Validation with Kolena
Kolena is an AI/ML testing & validation platform that solves one of AI’s biggest problems: the lack of trust in model effectiveness. The use cases for AI are enormous, but AI lacks trust from both builders and the public. It is our responsibility to build that trust with full transparency and explainability of ML model performance, not just from a high-level aggregate ‘accuracy’ number, but from rigorous testing and evaluation at scenario levels.
With Kolena, machine learning engineers and data scientists can uncover hidden machine learning model behaviors, easily identify gaps in the test data coverage, and truly learn where and why a model is underperforming, all in minutes not weeks. Kolena’s AI / ML model testing and validation solution helps developers build safe, reliable, and fair systems by allowing companies to instantly stitch together razor-sharp test cases from their data sets, enabling them to scrutinize AI/ML models in the precise scenarios those models will be unleashed upon the real world. Kolena platform transforms the current nature of AI development from experimental into an engineering discipline that can be trusted and automated.