What Is a Transformer Model?
A transformer model is a type of neural network architecture predominantly used in natural language processing (NLP). Unlike other AI models that process data sequentially, transformers handle data in parallel, which allows for faster processing times and the ability to handle long-range dependencies more effectively.
This architecture relies on a mechanism called attention, which selectively focuses on parts of the input data that are most relevant to the task at hand. Transformer models can simultaneously process all parts of the input sequence, speeding up tasks.
Transformers have become popular due to their efficiency and scalability. They have set new benchmarks in a variety of NLP tasks such as machine translation, text summarization, and content generation.
What Is Long Short-Term Memory (LSTM)?
Long Short-Term Memory (LSTM) is a kind of Recurrent Neural Network (RNN) architecture used primarily for sequential data processing. LSTMs can solve the vanishing gradient problem that can occur with standard RNNs, making them more effective for learning long-range dependencies within the input data.
This is achieved through gates that regulate information flow, which includes forget gates, input gates, and output gates, allowing it to maintain data over long sequences. LSTMs are widely used in applications where the sequence and time-series data are critical.
LSTMs have been successful in various time-series prediction tasks, speech recognition, and other applications that rely on maintaining context over long durations. Their structure allows them to remember past information for long periods, and they are capable of making predictions based on this remembered information.
This is part of a series of articles about generative models
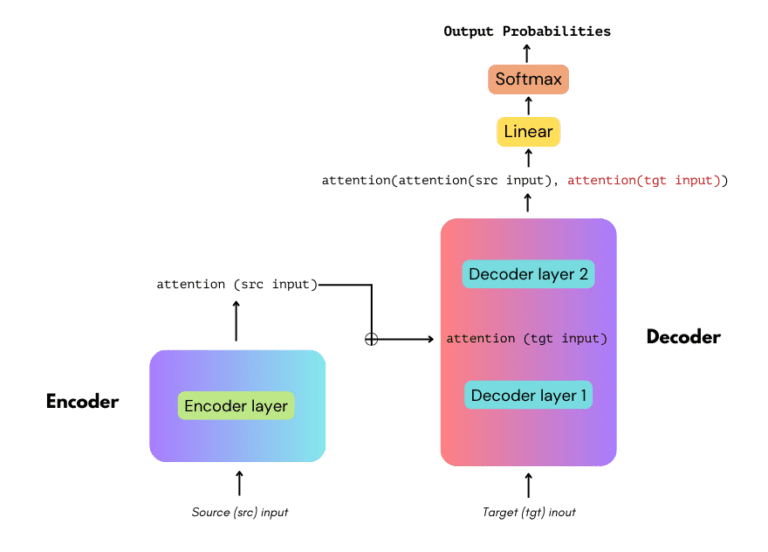
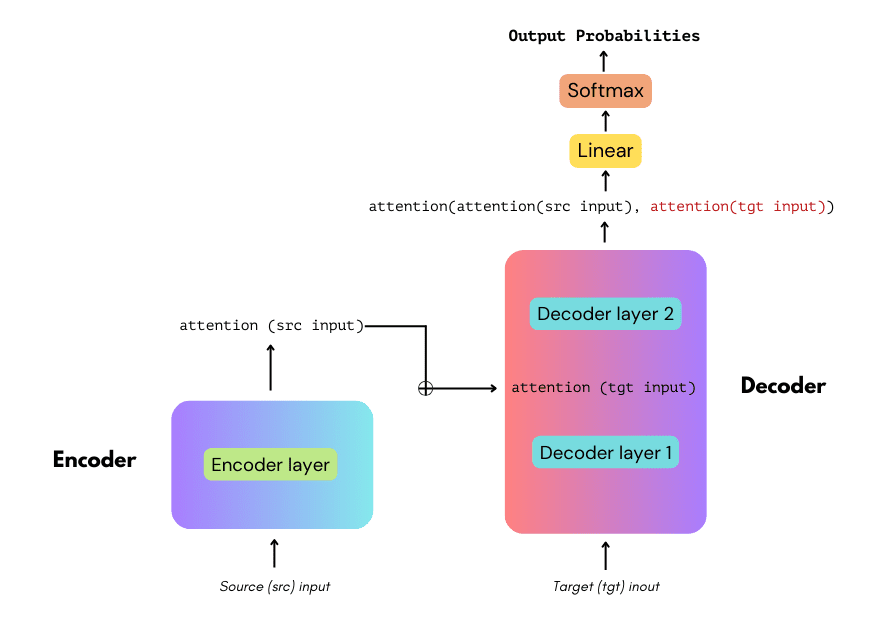
How Transformer Models Work
Transformers use an encoder-decoder structure. The encoder reads and processes the input text in fragments simultaneously and encodes it into a contextual representation. The decoder then reads this representation to generate the output sequentially.
This process relies on the attention mechanism, which allows the model to weigh the significance of different words in the input regardless of their position in the sequence.
Each layer of the transformer can attend to every other layer’s output simultaneously, making them highly parallelizable and significantly faster than architectures that require sequential processing.
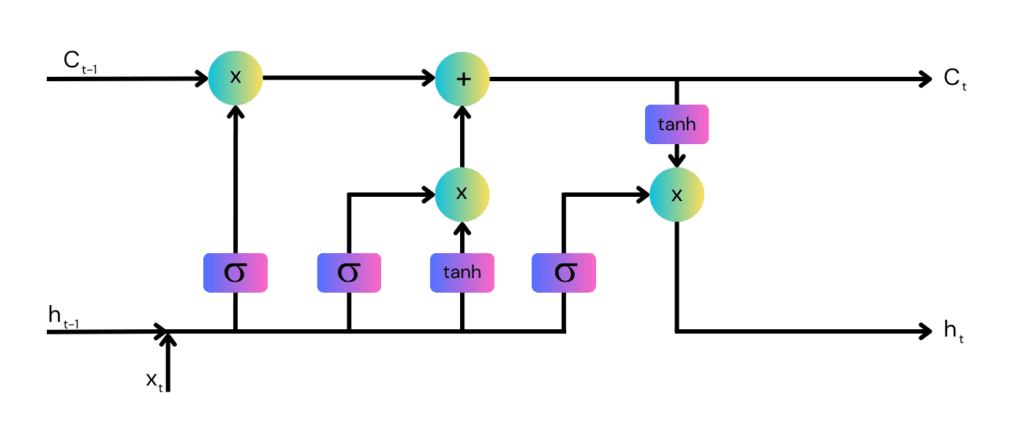
How LSTM Works
In an LSTM network, the flow of information is regulated by structures known as gates. Each cell in an LSTM can decide to keep or discard information based on the strength of the input and the context, provided by a mechanism called the cell state:
- Forget gates decide what information is irrelevant and can be thrown away.
- Input gates control the addition of new information to the cell state, and output gates determine what the next hidden state should be.
This selective memory capability enables LSTMs to make context-specific decisions about which information to store and for how long to store it, making them suitable for applications that involve complex dependencies over time. This could include language modeling where previous words dictate the meaning of subsequent ones, or stock price predictions where past trends can influence future prices.
Transformers vs LSTM: Key Differences
Let’s see how these two models differ in key areas.
1. Architectural Differences
Transformers eliminate the need for recurrent connections by using self-attention mechanisms to process data in parallel. The architectural efficiency of transformers allows for greater scalability and faster processing speeds when training on large datasets.
LSTMs, with their gate-based architecture, process data sequentially and rely on their recurrent structure to handle time-series or sequence data effectively. They carefully manage information across time, which can lead to slower training times compared to transformers but allows for more nuanced understanding and preservation of sequential information.
2. Sequential vs Parallel Processing
LSTMs process data points sequentially, meaning each step depends on the previous steps’ computations. This sequential dependency is critical for tasks where order and context play a major role in predictions, but it limits the processing speed and parallelizability of the model.
Transformers process elements of the sequence in parallel. This reduces the time needed for training and allows the model to handle more complex patterns or larger datasets. However, while beneficial for speed and efficiency, it may sometimes overlook the nuanced understanding of sequence inherent in LSTM.
3. Efficiency and Scaling
Transformers generally offer better efficiency and scaling capabilities than LSTMs. Their parallel processing ability not only makes them faster but also more suitable for deployment in large-scale applications, where processing large datasets in a reasonable timeframe is crucial. The scalability of transformers allows easier adaptation to various NLP tasks.
LSTMs, while capable of handling large datasets, do not scale as efficiently as transformers. Their sequential nature means that increasing dataset sizes or sequence lengths can lead to exponentially higher computation times, making them less suitable for tasks requiring rapid processing of large amounts of data.
4. Handling Dependencies
LSTMs are better at maintaining long-term relationships within the data, thanks to their gated structure and recurrent nature. This makes them particularly useful for applications where the integrity and understanding of the sequence are the priority, such as in speech recognition or time-series analysis.
Transformers, although efficient in processing data and identifying relationships, sometimes struggle with long-range dependencies due to their fixed-length context windows. However, advancements like the Transformer-XL seek to overcome this by allowing transformers to access extended context from previous segments.
Transformers vs LSTM: How to Choose?
For most NLP tasks, transformers are today considered to be the state of the art. However, LSTM-based systems still have their place for specific use cases.
When deciding between transformers and LSTMs for a given application, several key factors should be taken into account:
- Nature of the data: For sequential data where context and order are critical, such as time-series data or natural language tasks that rely heavily on the previous context, LSTMs might be more suitable due to their inherent ability to retain and manage long-term dependencies. If your data can benefit from parallel processing and efficiency is a priority, transformers are often the better choice.
- Computational resources: Transformers generally have lower computational requirements, due to their parallel processing capabilities. They can handle larger datasets and more complex models. LSTMs are slower to train and require more computational resources, both for training and inference.
- Task requirements: For tasks such as machine translation, text summarization, and other NLP applications where understanding and generating contextually accurate content across long texts is essential, transformers are often preferred due to their ability to handle long-range dependencies. For tasks requiring fine-grained understanding of sequential data, like time-series forecasting or speech recognition, LSTMs might provide better performance.
- Future scalability: If the project is expected to scale significantly, both in terms of data volume and complexity, transformers offer a more scalable solution due to their efficiency and ability to handle larger datasets more effectively. LSTMs might face challenges with very large sequences and data volumes, making them less suitable for highly scalable applications.
- Hybrid approaches: In some scenarios, combining the strengths of both models can yield better results. For example, using transformers to preprocess data or to handle parts of the data that can benefit from parallel processing, and then applying LSTMs for tasks that require detailed sequential understanding.
AI Testing & Validation with Kolena
Kolena is an AI/ML testing & validation platform that solves one of AI’s biggest problems: the lack of trust in model effectiveness. The use cases for AI are enormous, but AI lacks trust from both builders and the public. It is our responsibility to build that trust with full transparency and explainability of ML model performance, not just from a high-level aggregate ‘accuracy’ number, but from rigorous testing and evaluation at scenario levels.
With Kolena, machine learning engineers and data scientists can uncover hidden machine learning model behaviors, easily identify gaps in the test data coverage, and truly learn where and why a model is underperforming, all in minutes not weeks. Kolena’s AI / ML model testing and validation solution helps developers build safe, reliable, and fair systems by allowing companies to instantly stitch together razor-sharp test cases from their data sets, enabling them to scrutinize AI/ML models in the precise scenarios those models will be unleashed upon the real world. Kolena platform transforms the current nature of AI development from experimental into an engineering discipline that can be trusted and automated.