

What Is Inductive Bias in Machine Learning?
Inductive bias is the set of assumptions that a model uses to predict outputs given inputs that it has not encountered before. In machine learning, this term is paramount as it directly impacts a machine learning model’s ability to make accurate predictions.
Machine learning models are trained on a limited set of data and are then expected to make accurate predictions on new, unseen data. Inductive bias plays a crucial role in this process. The model has to make some assumptions, or inductive biases, about the unseen data to make a prediction. These biases are based on the data the model has been trained on.
Inductive bias in machine learning can be of two types:
- Preference bias: Refers to a model’s bias towards selecting certain functions over others when attempting to learn from the training data.
- Restriction bias: A model’s bias to only consider a limited subset of functions when learning from training data.
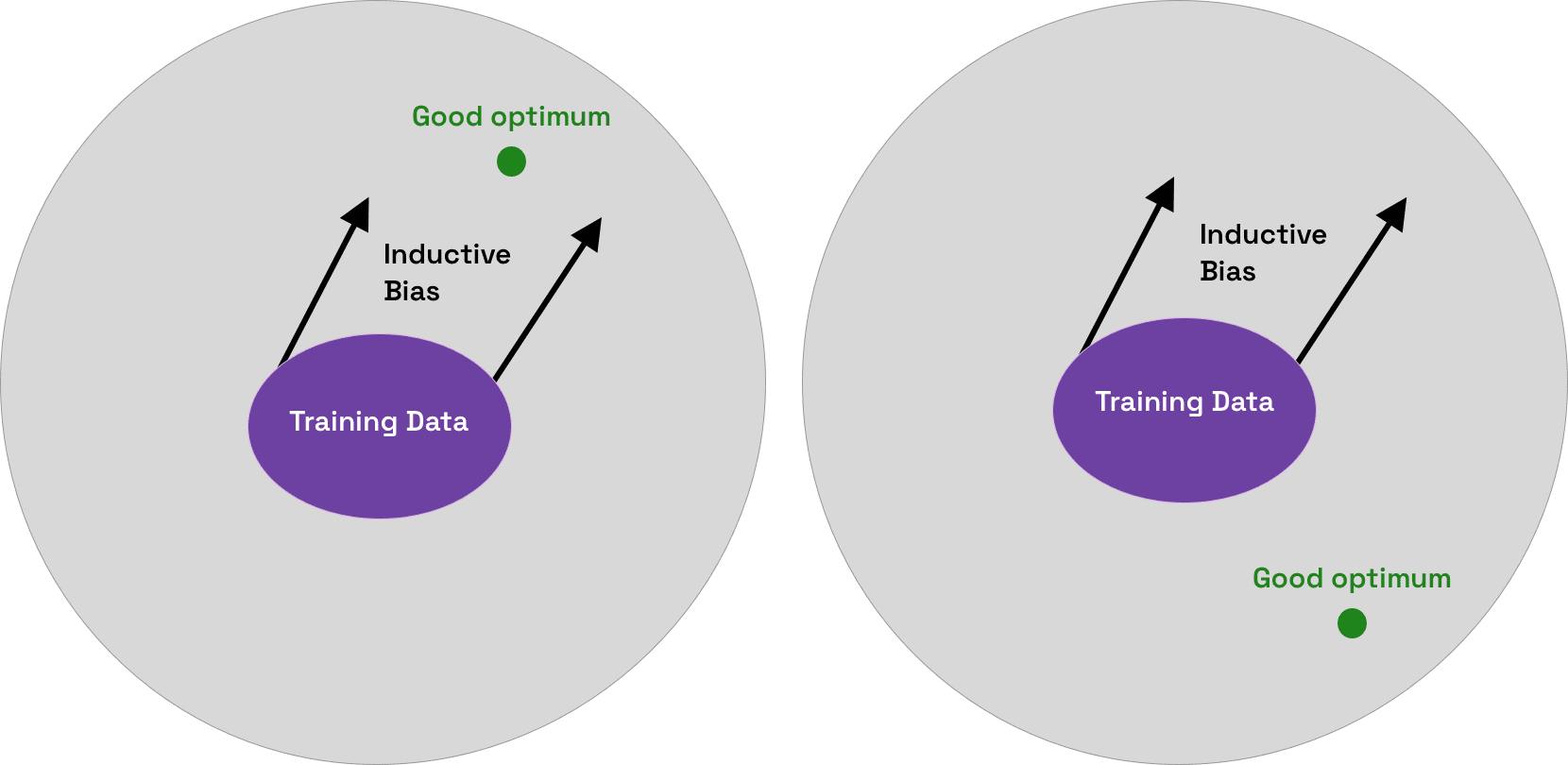
The image below illustrates how inductive bias can be helpful or unhelpful for a machine learning model. If the training data guides the model in the direction of a good optimum, which results in accurate predictions, the inductive bias can be considered helpful or ‘good’. However, if the inductive bias leads the model in the direction of an optimum that results in inaccurate predictions, it is unhelpful or ‘bad’.
Why Is Inductive Bias Important for Machine Learning Performance?
Here are some specific benefits of inductive bias, when appropriately applied, to machine learning model performance.
Enables Generalization
In machine learning, generalization is the model’s ability to adapt properly to new, unseen data after being trained on a limited data set. Without inductive bias, a model can’t make accurate predictions on unseen data, rendering it ineffective.
Inductive bias acts as a guide for the model when it encounters new data. It uses the assumptions (biases) made during training to make educated guesses about the unseen data. This allows the model to make predictions, even on data it has not encountered before, thereby generalizing from the training data to unseen data.
However, the quality of generalization heavily depends on the quality of the inductive bias. If the inductive bias is based on good assumptions about the data, the model will generalize well. On the other hand, if the inductive bias is based on poor assumptions, the model will not generalize well.
Guides the Learning Process
Inductive bias provides the model with a framework to learn from the data. It guides the model by telling it what to pay attention to in the data. For example, if the inductive bias is that the output is likely to be a linear function of the input, the model will pay more attention to linear relationships in the data. This guiding principle helps the model focus its learning and make better predictions.
Inductive bias also helps the model decide what not to learn (this is known as restrictive bias). For example, if the inductive bias is that the output is unlikely to be a complex function of the input, the model will ignore complex relationships in the data. This helps prevent the model from overfitting to the training data.
Addresses Overfitting and Underfitting
Finally, inductive bias is crucial in addressing two common problems in machine learning: overfitting and underfitting. Overfitting occurs when the model fits the training data too closely and fails to generalize to unseen data. On the other hand, underfitting occurs when the model fails to capture the underlying structure of the data and performs poorly on both the training and unseen data.
Inductive bias helps address these problems by providing a balance between fitting the training data and generalizing to unseen data. A good inductive bias allows the model to fit the training data well while also being able to make accurate predictions on unseen data.
Examples of Inductive Biases of ML Models
Every machine learning model has its unique inductive bias, which guides the learning process and helps determine the best hypothesis from the hypothesis space. These biases essentially shape the model’s learning ability. Let’s explore inductive biases in common machine learning models.
Regression Models
Regression models, such as linear regression and logistic regression, primarily use restriction bias, which restricts the hypothesis space to a particular function form. For instance, linear regression assumes that the relationship between input and output variables is linear. This assumption is a form of inductive bias. However, such a bias can limit the model’s ability to learn from complex data sets where the relationship between variables is non-linear.
Decision Trees
In decision trees, inductive bias stems from the preference for shorter, simpler trees over larger, more complex ones. This is known as a ‘preference bias.’
When a decision tree is trained on a dataset, it prefers hypotheses that place the most crucial attributes near the root of the tree. This preference makes decision trees efficient and easy to understand. However, like any bias, it can limit the model’s performance, if crucial attributes are not near the root.
Bayesian Models
Bayesian models, named after Bayes’ theorem, operate on the inductive bias of statistical independence between features. This assumption allows these models to calculate the probability of an event based on prior knowledge of conditions that might be related to the event.
However, the independence assumption may not always hold true. In real-world scenarios, features often influence one another. Despite this limitation, Bayesian models have been successful in many domains, such as spam filtering and document classification, where the independence assumption is reasonably accurate.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a type of deep learning model predominantly used in image processing tasks. The inductive bias in CNNs comes from their architectural design, which assumes that inputs (like pixels in an image) that are close to each other are more related than those further apart. Specific CNN architectures have been shown to have additional biases, such as a bias towards using shape or texture, rather than color, to classify images.
This architectural bias enables CNNs to excel in tasks involving spatial data, such as image and video recognition. However, this bias may limit their effectiveness in tasks where proximity of inputs does not imply a stronger relationship, or where shape and texture are not good predictors of an image’s label.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are designed to handle sequential data, such as time series or natural language. The inductive bias in RNNs is their ability to maintain a form of memory through their hidden states, which helps them understand and predict sequences by considering the context provided by previous elements in the sequence. This bias is particularly evident in tasks like language translation or speech recognition, where understanding the sequence of inputs is crucial for accurate predictions.
However, the sequential processing nature of RNNs can be a limitation. They may struggle with very long sequences due to issues like vanishing or exploding gradients, where the influence of input data either diminishes or becomes excessively large over many time steps. This can make it challenging for RNNs to capture long-term dependencies within the data, which is a significant consideration in some applications.
Transformers
Transformers, a newer class of models in machine learning, have gained significant attention for their effectiveness in handling sequential data, especially in natural language processing. Unlike RNNs, Transformers do not process data in sequence. Instead, they use a mechanism called attention, allowing the model to weigh the importance of different parts of the input data regardless of their position in the sequence. This approach provides Transformers with an inductive bias that is adept at handling long-range dependencies and parallel processing, making them highly efficient for large-scale language tasks.
The main drawback is Transformers perform worse when limited training data is available. Researchers from Meta have proposed ‘injecting’ bias into Transformers, essentially making them similar to CNNs, to help them deal with limited data scenarios.
Graph Neural Networks (GNNs)
Graph Neural Networks (GNNs) are a type of neural network designed to handle graph-structured data. The inductive bias in GNNs comes from their ability to aggregate information from a node’s immediate neighborhood.
This bias enables GNNs to excel in tasks involving social network analysis, molecule structure analysis, and recommendation systems. However, they may struggle with tasks that require understanding more complex, non-local relationships within the graph.
5 Ways to Ensure ML Inductive Bias Helps Model Performance
Here are a few ways you can ensure inductive bias works well in your models to improve performance on real-life inputs.
1. Diverse and Representative Training Data
It is important to ensure that your training data is diverse and representative. This means that the data used to train the machine model should accurately represent the kinds of data it will encounter in the real world. This includes a range of different types of data and scenarios.
For instance, if you’re training a machine learning model to detect spam emails, your training data should include a broad spectrum of emails – not just those that are obviously spam or not-spam. It should also cover different email formats, subjects, and styles of writing. This diverse training data will help the machine model understand the complexity and variety of real-world data.
2. Cross-Validation Techniques
Another effective method for optimizing machine learning inductive bias is the use of cross-validation techniques. Cross-validation is a process where a model is trained on a subset of the data and then tested on the unseen data. This process is repeated several times, with different subsets used for training and testing each time.
Cross-validation helps in assessing how the results of a statistical analysis will generalize to an independent data set. It is mainly used in settings where the goal is the prediction, and you need to estimate how accurately a predictive model will perform in practice. This technique can help identify ineffective inductive bias present in the model and correct it before it affects the model’s performance.
3. Utilize Ensemble Learning Techniques
Ensemble learning involves combining the predictions of multiple machine learning models to make a final prediction. This can help even out the biases of individual models and can often lead to more accurate predictions.
Ensemble learning techniques like bagging, boosting, and stacking can be used to reduce the risk of inappropriate inductive bias. These techniques combine the predictions of multiple models, each with their own inductive biases, to create a final prediction that is often more accurate than any single model.
4. Regularly Monitor for Data Drift
Data drift occurs when the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways. This can lead to a model’s performance degrading over time. This is a form of unhelpful inductive bias, because the model is making decisions based on old training data, which might no longer be relevant. By regularly monitoring your machine learning models for data drift, you can detect changes in the underlying data distribution and retrain or tune your models accordingly.
5. Test ML Models Rigorously
Rigorous testing of machine learning models is crucial to ensure that the inductive bias does not lead to poor generalization on unseen data. Testing involves evaluating a model’s performance under various conditions and scenarios that it might encounter in real-world applications. This process helps in identifying and mitigating issues such as bias, overfitting, and underfitting, thereby enhancing the model’s reliability and robustness.
One effective approach for rigorous testing is to use a diverse set of test datasets that are separate from the training data. These datasets should represent the variety of scenarios and data distributions the model is likely to encounter in actual use. For instance, in a facial recognition system, the test data should include faces with various expressions, lighting conditions, and angles, and not just the scenarios seen during training.
Another aspect of rigorous testing is stress testing, which involves evaluating how the model performs under extreme or unexpected conditions. This could include feeding the model with noisy or incomplete data, or data that significantly deviates from the training set. The goal is to understand the limits of the model’s capabilities and the conditions under which its performance degrades.
Testing and Evaluating ML Models with Kolena
Kolena makes robust and systematic ML testing easy and accessible for all organizations. With Kolena, machine learning engineers and data scientists can uncover hidden machine learning model behaviors, easily identify gaps in the test data coverage, and truly learn where and why a model is underperforming, all in minutes not weeks. Kolena’s AI / ML model testing and validation solution helps developers build safe, reliable, and fair systems by allowing companies to instantly stitch together razor-sharp test cases from their data sets, enabling them to scrutinize AI/ML models in the precise scenarios those models will be unleashed upon the real world. Kolena platform transforms the current nature of AI development from experimental into an engineering discipline that can be trusted and automated.
Among its many capabilities, Kolena also helps with feature importance evaluation, and allows auto-tagging features. It can also display the distribution of various features in your datasets.
Reach out to us to learn how the Kolena platform can help build a culture of AI quality for your team.


