
AutoArena
Evaluate LLMs, RAG systems, and generative AI applications using automated head-to-head judgement. Trustworthy evaluation is within reach.
Testing Generative AI applications doesn't need to hurt
Fast, accurate, cost-effective — automated head-to-head evaluation is a reliable way to find the best version of your system.
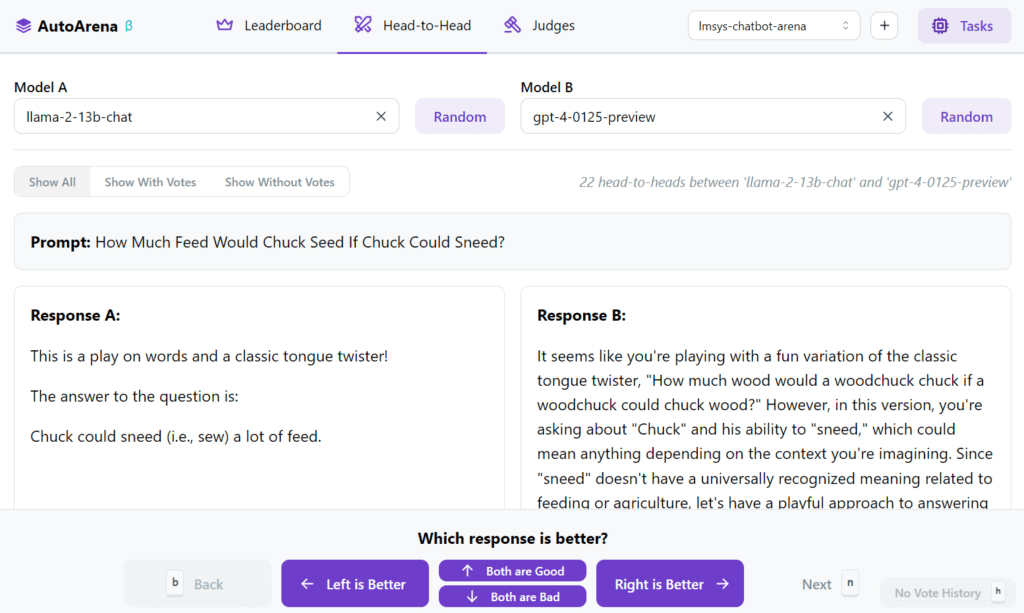
Head-to-head
evaluation using judge models yields trustworthy results
LLM-as-a-judge is a proven technique and judge models generally perform better in pairwise comparison than when evaluating single responses. Turn many head-to-head votes into leaderboard rankings by computing Elo scores and Confidence Intervals
Use "juries" of LLM judges
Multiple smaller, faster, and cheaper judge models tends to produce a more reliable signal than a single frontier model. Let AutoArena handle parallelization, randomization, correcting bad responses, retrying, rate limiting, and more so that you don't have to.
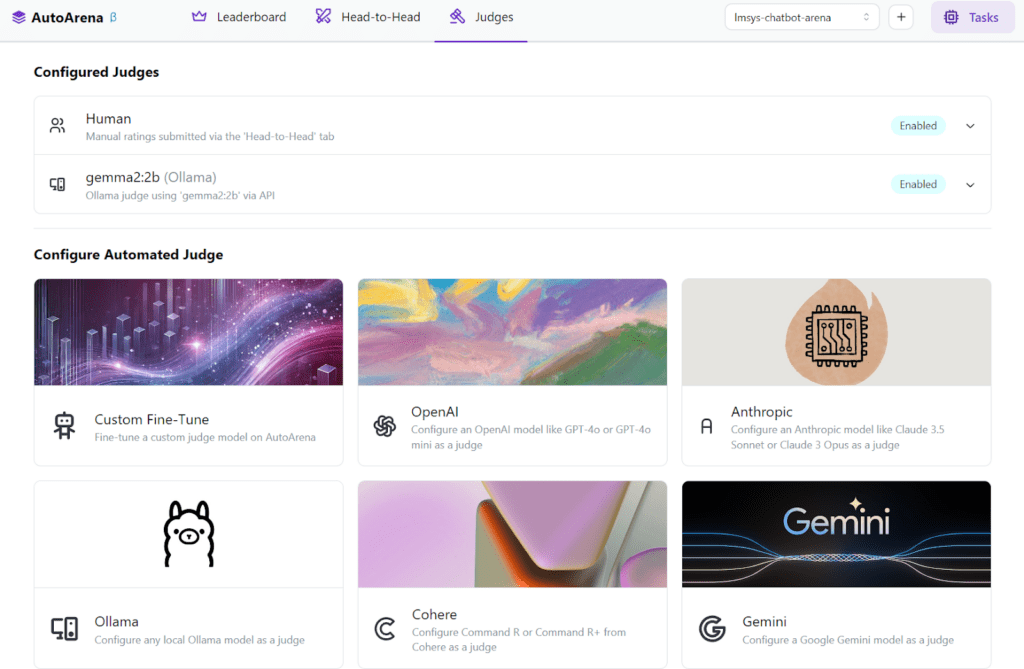
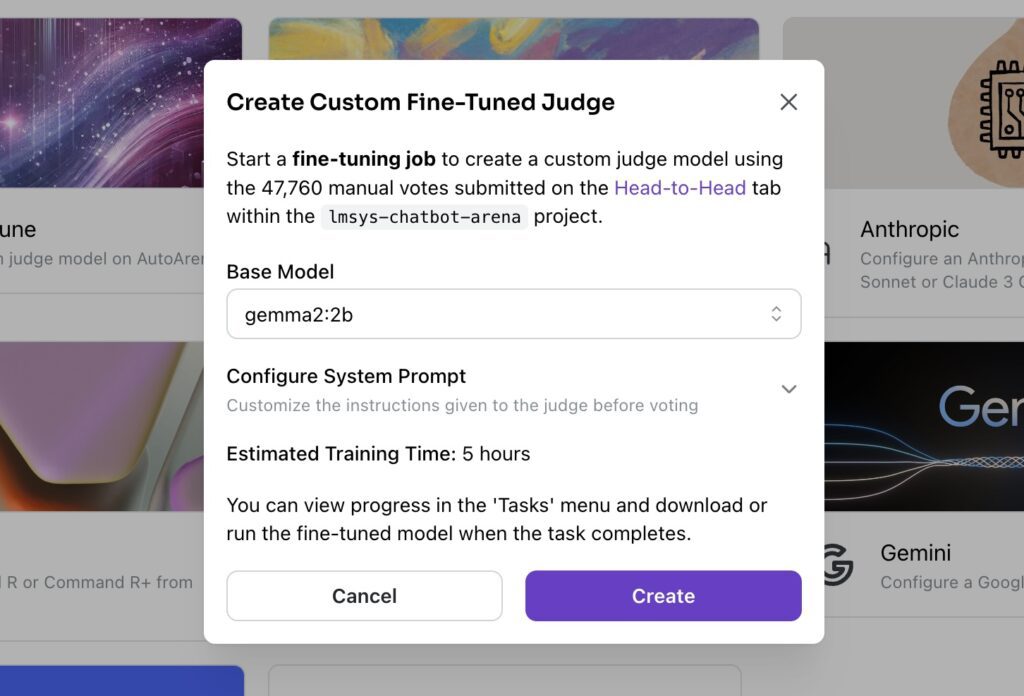
Fine-tune judges
Use the head-to-head voting interface to collect human preferences that can be leveraged for custom judge fine-tuning on AutoArena. Achieve >10% accuracy improvements for human preference alignment over frontier models.

See AutoArena in Action