
Machine learning engineers and data scientists spend most of their time testing and validating their models’ performance. But as machine learning products become more integral to our daily lives, the importance of rigorously testing model behavior will only increase. It is rapidly becoming vital for ML teams to have a full understanding of when and how their models fail and to track these cases across different model versions to be able to identify regression. The consequences of deploying models without fully understanding their strengths and weaknesses could even have life-threatening implications in some applications.
At Kolena, we believe current ML evaluation techniques are falling short in their attempts to describe the full picture of model performance. Evaluating ML models by only using a single metric (like accuracy or F1 score), for example, produces a low-resolution picture of a model’s performance.
“Overall statistics don’t provide information on the distribution of failures across types of cases, attributes, scenarios. Even when upgrades show higher overall accuracy, surprising shifts can occur in the distribution of errors, including new ones.”
– Eric Horvitz, Chief Scientific Officer at Microsoft
We’ve seen great results from teams implementing unit and functional testing techniques in their model testing. In this post, we’ll cover why systematic unit testing is important and how to effectively test ML system behavior.
The Importance of Systematic ML Unit Testing
A recent discovery on Twitter’s racially biased cropping algorithm is a good example of the importance of systematic ML unit testing. When you upload an image or link to Twitter, the algorithm automatically crops the image to center on a human face in the preview image. However, it has been observed that when an image contains both a black person and a white person, the algorithm chooses to center the white person’s face in the preview in most cases.

An example of racial bias in Twitter’s cropping algorithm (Source)
These biases are actually more common than we think. In September 2020, a PhD student in Canada tweeted about a black professor’s face being removed when a virtual background was used.
Although these examples of racial bias in facial recognition/detection technology are good indications that the teams who build these technologies must accurately identify bias before products are launched, racial bias is not the only scenario where we want to test model robustness. We also need to test a model’s robustness to other characteristics, such as age, gender, camera and weather conditions, occlusion of important features like eyes and mouth, etc. An aggregate performance metric (e.g. 98% accuracy) leaves huge blind spots as to how the model performs on these different subclasses, a phenomenon that is called the hidden stratification problem.
What is hidden stratification?
In real-world ML tasks, each labeled class consists of multiple semantically distinct subclasses that are unlabeled. Because models are typically trained to maximize global metrics such as average accuracy, they often “silently fail” on important subclasses. This phenomenon leads to skewed assessments of model quality and results in unexpectedly poor performance when models are deployed.
Let’s take a closer look at the hidden stratification problem and borrow some concepts from software engineering testing best practices to solve the problem.
Mitigating the Hidden Stratification problem
As we mentioned in the previous section, the current go-to approach for evaluating a model’s performance is to hold out a random sample of data for testing, then produce a global performance metric. In software, this is equivalent to selecting a random set of features in a software product, then producing a test report that says, “Your system passes on 95% of the features that you randomly selected to test!” But what are the tests that passed? Which ones failed? What has improved? What has regressed? All of the answers to those questions are currently unknown and will require weeks of diligent, manual investigation by data scientists.
What we need is a paradigm shift away from a world of large, arbitrarily split test datasets to one of fine-grained, well-curated test cases, each one built to test a specific feature learned by the model (e.g. noise, lighting, occlusion, etc.). This would be a world where data scientists can test the skills learned by the model, not the metrics.
Unit testing for machine learning
To this end, Marco Ribeiro et al., presented a new ML evaluation methodology in their paper “ Beyond Accuracy: Behavioral Testing of NLP models with CheckList.” The proposed approach is based on a breakdown of potential linguistic capability failures into specific test cases, which is similar to the traditional software systems testing approach. Here, a unit test that focuses on a specific capability or failure mode can be generated by collecting small but focused testing dataset or by slicing the original dataset into specific attributes. In other words, the authors propose that we break a given Class into smaller subclasses for fine-grained results. Each subclass represents a specific scenario or attributes to be evaluated independently. This will become much clearer in the example coming next.
Let’s see how this approach works on ML models. First, we’ll borrow the following concepts from software engineering testing best practices:
- Unit test: it is testing an individual software function or system component in isolation to validate that each unit performs as expected. In ML, a unit can represent a specific scenario or set of attributes within the labeled Class.
- Test case: a collection of data samples (images, rows, text) that represent a specific scenario to be tested.
- Test suite: a group of test cases that have shared properties to achieve a testing objective (e.g. smoke, integration, regression tests, etc.).
- Smoke testing: a quick way to assess whether important capabilities are broken or not instead of running inferences on the entire list of cases.
Next, we’ll scope out how to apply this approach in the computer vision space by using a simple one-class object detection model. Suppose we want to build a Car Detector. In the table below, we can quickly break down the CAR class into test cases to illustrate the concepts.

Breaking down a class in this manner provides us a better understanding of how the model performs at a granular level. With the proper tooling, we can run tests on other specific test cases or suites for quick verification during development, or we can run full regression tests before a release. These steps can be repeated with every test even after deployment. In fact, whenever we face an unexpected scenario in deployment, we can generate a new test case for that particular behavior, then over time, the team can build more comprehensive and more exhaustive test suites for a variety of tasks and build a detailed report on a model’s performance in each capability category to compare it to a baseline model.
Furthermore, we’re now able to make more informed comparisons between different models and choose the most fitting model for our use case. Instead of comparing models based on their global metrics, we can compare models based on their prediction capabilities or test cases.

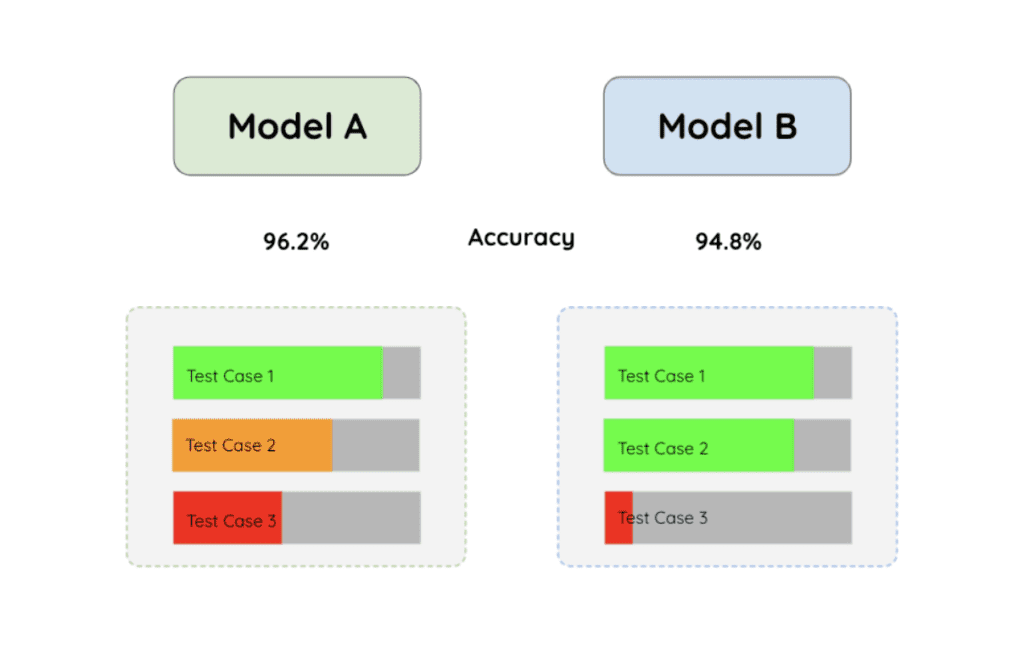
Model comparison using unit testing. Figure adapted from Jay Alammar’s video on YouTube
Why unit testing for machine learning?
In the figure above, suppose we have two models, A and B, and their accuracy is 96.2% and 94.8%, respectively. While Model B has lower overall accuracy, it could be a better fit for a use case or deployment that cares more about test cases 1 and 2. This shows that the overall metric doesn’t give enough picture about how the models really behave.
We’ve seen teams that are implementing unit testing achieving great model quality results and faster iterations, which aligns with our expectations because implementing unit tests for ML allows teams to:
- Identify failure modes. The team can get a granular understanding of model behavior for each scenario.
- Reduce model experimentations and avoid shooting in the dark. Identifying failure modes saves a huge amount of time and effort during model training and data collection because teams now know the exact issues (bugs) that they need to improve.
- Build central organization knowledge. Good unit tests serve as project documentation for product success criteria.
Note that in our earlier Car Detector example, we listed only 14 test cases to illustrate the unit testing concept. In real-world scenarios, this number would grow through time to tens of test cases per labeled class. For an average model that detects ~5–20 classes, the number of test cases rapidly explodes to hundreds of test cases per model.
As you can imagine, this ends up being a fairly large amount of work — not only do we have to curate different test cases across the board, but we also have to maintain them, keep track of versions and failure modes, and compare the models in all these cases. This quickly becomes a huge engineering effort, and many teams will opt to focus their development efforts on building out new models at the expense of having model quality standards.
At Kolena, we’re building a next-generation ML testing and validation platform that speeds up the ML unit testing and validation process at scale. If you want to learn more about everything ML testing and how it can help your own shop, drop us a note at info@kolena.io. We would love to hear your thoughts and brainstorm some solutions for your own use cases.


