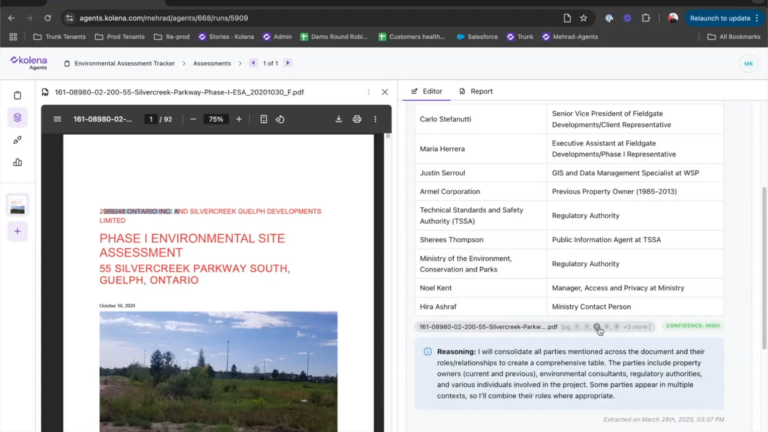
Evaluating language models, retrieval-augmented generation (RAG) setups, and different prompt configurations typically requires time-consuming manual efforts. AutoArena simplifies this by automating head-to-head contests with LLM judges, which quickly generates trustworthy evaluations and makes it easy to identify your best-performing system variations.
In this tutorial, we’ll dive into the core steps for getting started with AutoArena. You’ll install the tool, configure it for head-to-head evaluations, and use automated judges to rank models. Let’s walk through it step-by-step.
First, Why Head-to-Head Evaluation?
Human-like judgment: Human preference is at the core of many AI applications, and head-to-head evaluation captures how humans would make subjective judgments.
Applicable to ambiguous tasks: Many real-world tasks involve nuance and subjective interpretation, which head-to-head evaluations reflect better than static metrics.
Ranking with confidence: Using methods like the Elo rating system, multiple head-to-head comparisons can generate global rankings for models. This offers more confidence than single-instance evaluations.
AutoArena
AutoArena is an open source tool that allows you to automatically stack rank different versions of your Gen AI system. This includes comparing models, adjusting prompts, or modifying the way you retrieve context from a RAG system. The app automates the head-to-head comparison of model outputs and feeds the results into an Elo score, which generates a global leaderboard showing which version of your system performs best.
Automated, side-by-side comparison of model outputs has become a prevalent evaluation practice (arXiv:2402.10524). AutoArena is built around this technique, making it easier than ever to set up and run comprehensive evaluations for your models.
Key Features:
🏆 Rank outputs from LLMs, RAG setups, and prompts to find the optimal configuration.
⚔️ Automated head-to-head evaluations with auto-judges using local models or leading APIs such as OpenAI, Anthropic, and Cohere.
🤖 Custom judges can connect to your internal services or implement bespoke logic.
💻 Run locally with full control over your environment and data.
Star the autoarena repo
1. Installing AutoArena
The first step to using AutoArena is to install it locally. With Python installed on your machine, you can simply use the following command to install AutoArena:
pip install autoarena
That’s it! You now have AutoArena. You can launch AutoArena with the following command:
python -m autoarena
The AutoArena interface is now available in your browser at http://localhost:8899. From here, you can manage projects, upload model outputs, and view evaluation results.
2. Setting Up a Project
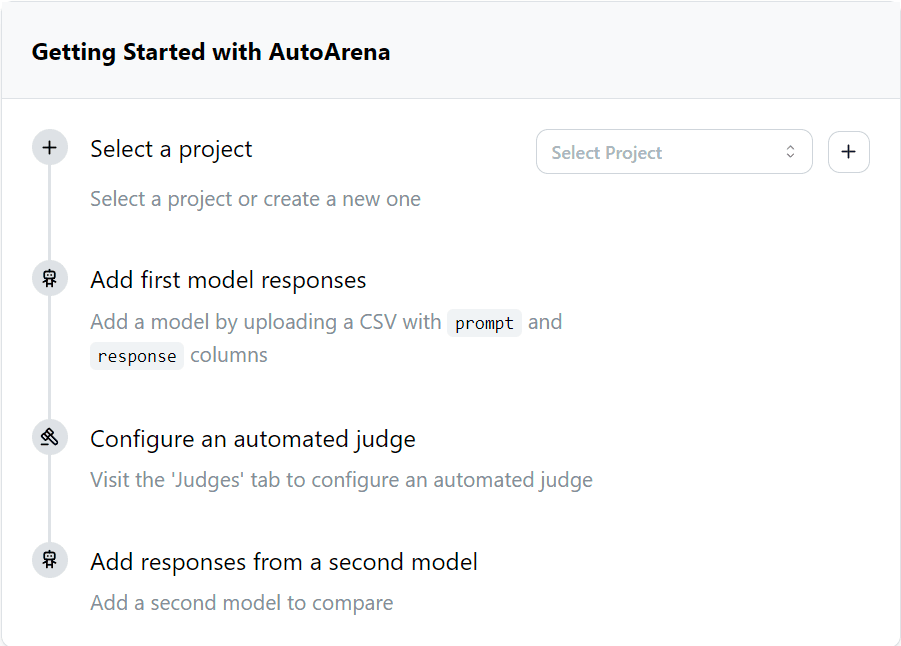
After launching AutoArena, you’ll need to create a new project. This is where you’ll manage model comparisons and evaluations.
- Create a new project in the UI. If this is your first project you will be presented with a step-by-step guide.
- Upload a CSV file with prompt and response columns—this represents the input prompts and the corresponding model outputs.
- Do this for a second model’s outputs to the same inputs. These two sets of outputs can then be compared by judges. You can add results from as many models as you want to compare.
📂 Data Storage
Data is stored in ./data/<project>.duckdb files in the directory where you invoked AutoArena. See data/README.md for more details on data storage in AutoArena.
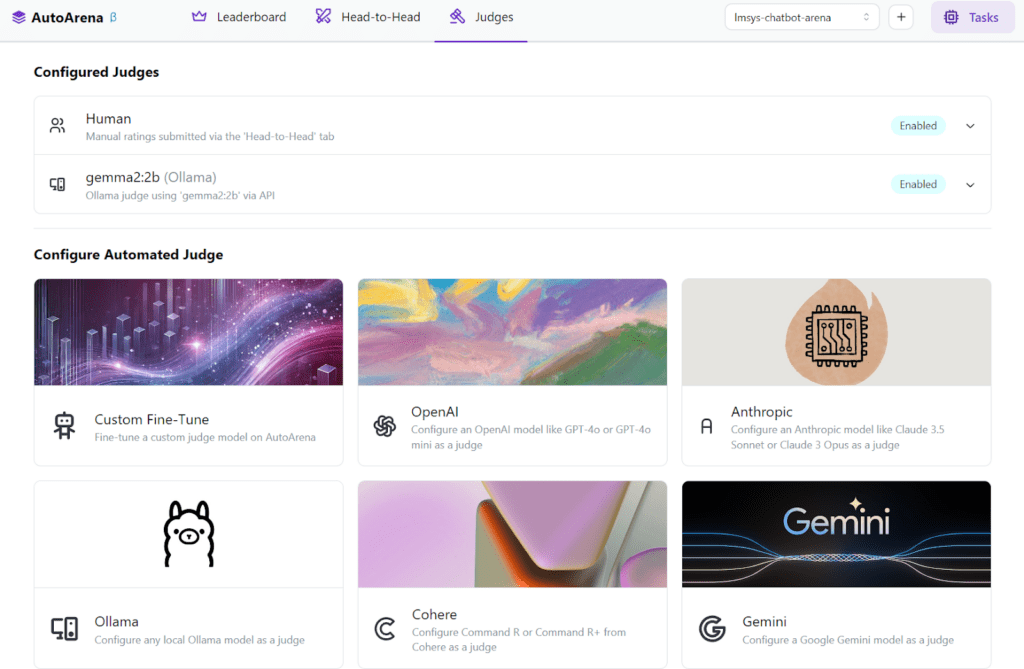
3. Configuring Judges
Judges perform the head-to-head decisions to generate results. Once the judges are chosen, whenever you upload model results, AutoArena will automatically match up the new data points against previously tested models for comparison.
- Automated Judges: Simply choose local models or models provided by one of the available external providers (OpenAI, Anthropic, Cohere, etc.) to set it as one of your automated evaluators.
- Custom Judges: Connect to your internal APIs or specify judging logic tailored to your requirements.
To configure a judge:
- Click the Judges tab.
- Choose from your own local models to run via Ollama, or external judges via API.
- For external judges, you will need a provider API key set as an environment variable in the environment running AutoArena.
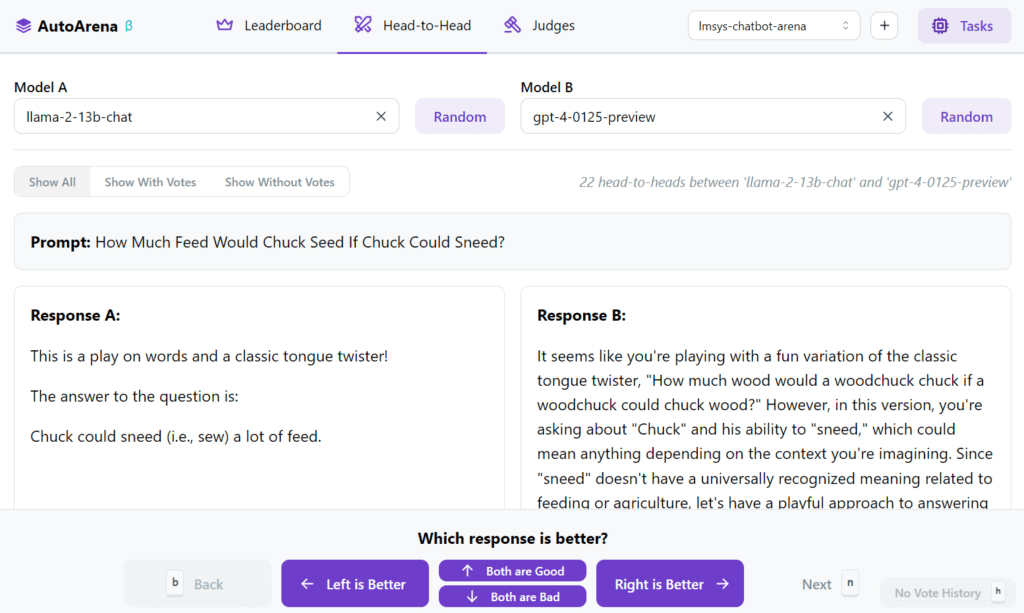
Human judging:
You can participate as a human judge alongside any automated judges by clicking the Head-to-Head tab and choosing two sets of model outputs to compare side-by-side. Each vote updates Elo scores and adjusts the leaderboard rankings.
AutoArena allows you to fine-tune custom judges based on your collected ratings. You can fine-tune a judge model to get better classification accuracy based on human judgment once enough manual ratings are collected (usually 100–2,000 for simple tasks).
4. Running Evaluations
Once your judges are set, any new model uploads will automatically trigger automated judgments. You can manually trigger evaluations as well:
- Click Run Automated Judgment in any expanded model view on the leaderboard.
- AutoArena will perform the head-to-head comparison using the judge system you configured.
- You’ll receive scores for each model, allowing you to easily see which one performs best.
You can track the progress of any active evaluation processes by clicking the Tasks button in the upper right of the interface.
AutoArena tracks the judging history for any model pair. You can review how the automated judges voted and compare their decisions with the human ratings, providing deeper insights into where models perform well or struggle.
5. Viewing Results
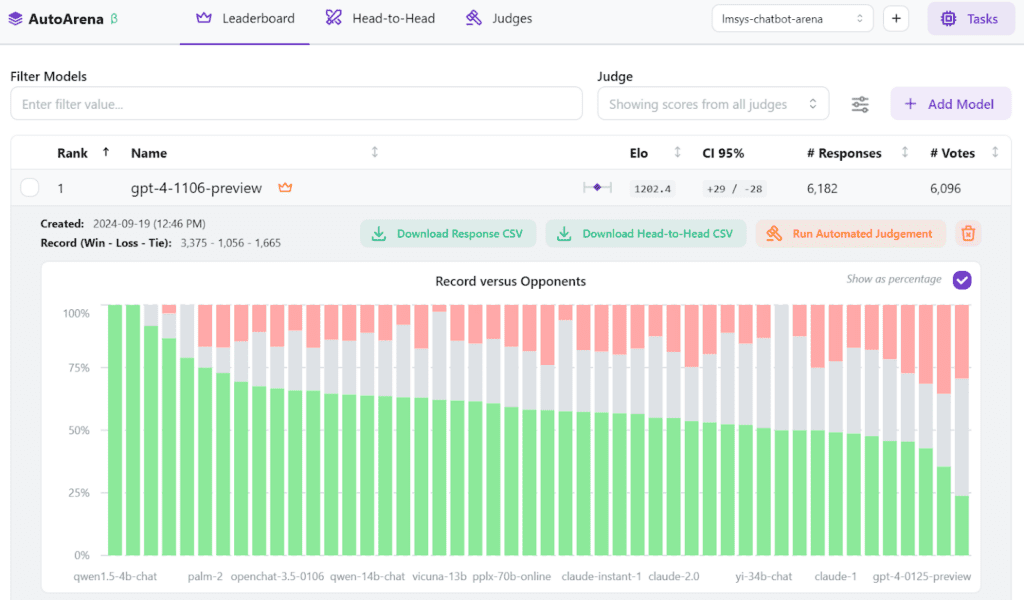
The Leaderboard page maintains the latest computed rankings for any model results you have uploaded. For each model, you get an associated Elo score, a 95% confidence interval range, the number of data points uploaded from that model, and the number of votes contributing to the Elo score.
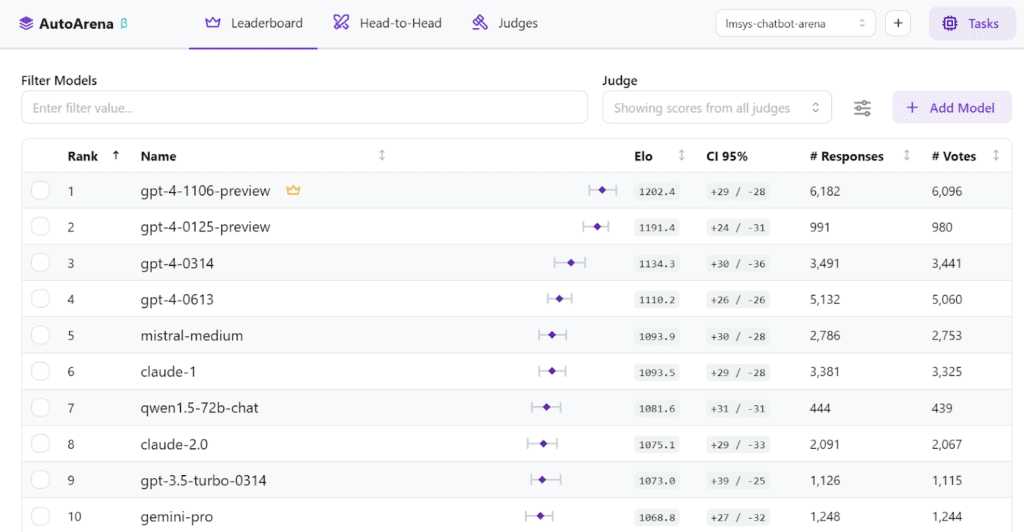
Clicking on any row lets you track how the model’s score has changed over time, along with the details of which head-to-head matchups it has won, lost, or tied.
6. Using Results
Once you have the results from AutoArena’s evaluations, there are several concrete ways to leverage them for improving your AI systems:
1. Focus Faster on the Best Models
The first and most obvious use of the results is to quickly identify the best-performing models or system configurations. The Leaderboard sorts to show the models performing the best across your entire set of variations. This helps you make faster decisions about which models to continue developing, fine-tuning, or deploying.
2. Supplement with Human Evaluation
Use the head-to-head comparison tool to manually vote on a few model outputs. Votes are automatically incorporated into the leaderboard rankings, ensuring that human preferences are reflected in the overall performance evaluation.
3. Speed Up Iteration Cycles
With AutoArena’s automated comparison and ranking, you can quickly test new models, RAG configurations, or prompt adjustments by simply uploading their outputs. This drastically reduces the time required for manual testing, enabling faster iterations and quicker decision-making on which versions to move forward with and lets you feed from automated data pipelines to test new experiments automatically.
Star the AutoArena repo on GitHub to keep up with updates
Why not just have a single judge directly score model outputs?
LLMs are better at judging responses head-to-head than they are in isolation
Research shows that leaderboard rankings computed using Elo scores from side-by-side comparisons are more reliable than those based on isolated metrics (arXiv:2408.08688). This is because head-to-head evaluations offer clearer insights into how models perform on real-world tasks, where “correct” answers can be subjective or ambiguous.
LMSYS Chatbot Arena is now considered by many a more trusted source for foundation model performance compared to traditional benchmarks (arXiv:2403.04132).
Juries are better than judges
Using a “jury” of multiple smaller models from different families—like GPT-4o-mini, Command-R, and Claude-3-haiku—has also proven to yield better accuracy than relying on a single large judge model like GPT-4o. This method, known as PoLL (Panel of LLM Evaluators), not only boosts accuracy but also runs faster and is cheaper (arXiv:2404.18796).
Summary
AutoArena automates the head-to-head evaluation process, providing fast, scalable, and accurate insights into model performance. With its ability to handle both automated judges and custom fine-tuned models, it simplifies the task of comparing different versions of AI systems. Whether you’re tweaking prompts, comparing models, or testing different RAG configurations, AutoArena provides a practical, data-driven way to find the best-performing setup.
Join the AutoArena Slack community! We’d love to hear about your experience using the tool.