The Challenge of Evaluating AI Models
As AI systems, particularly large language models (LLMs), become more advanced, evaluating their performance has grown increasingly complex. Traditional metrics like BLEU and ROUGE focus on superficial, string-based matching, often missing critical aspects like fluency, creativity, and relevance—qualities essential for tasks like text generation and question answering. Developers and researchers alike face the challenge of evaluating models in a way that truly reflects how well they perform in real-world scenarios.
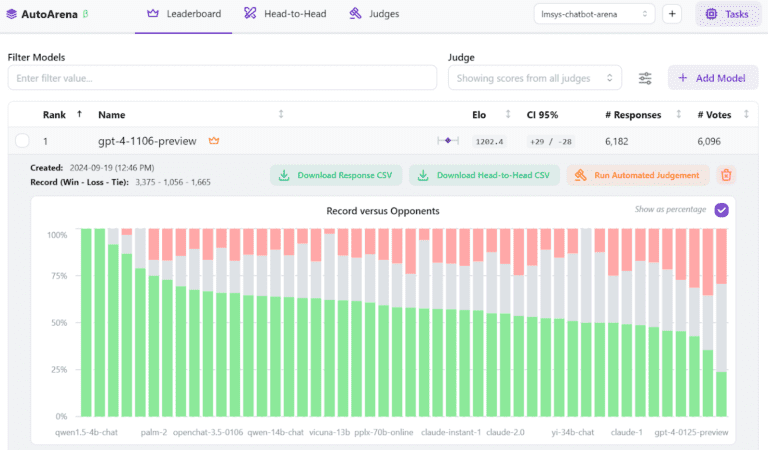
AutoArena addresses this challenge with a novel approach: head-to-head evaluations with Elo scoring and LLM judges. Instead of relying solely on static benchmarks, AutoArena compares models by directly pitting their outputs against one another, using LLM-based evaluators alongside human judgements. The results feed into an Elo-based ranking system, producing a dynamic, evolving leaderboard that shows which models excel at any specified task.
In this blog post, we’ll explain how head-to-head evaluations work, how Elo scoring is applied to create trustworthy rankings, and why AutoArena’s method is scientifically backed to deliver accurate, reliable results.
1. The Shortcomings of Traditional Evaluation Metrics
For years, AI evaluation has relied on traditional metrics like BLEU, ROUGE, and perplexity. These metrics are useful for tasks like machine translation or summarization, where direct comparison between generated text and a reference text is feasible. However, they are fundamentally flawed for evaluating free-form, generative tasks like text generation, where there are multiple valid ways to answer a prompt or respond to a question.
Why do these metrics fall short?
- String-based limitations: Metrics like BLEU and ROUGE primarily focus on string overlap between generated text and a reference answer. While this works well for translations or extractive summarization, it doesn’t account for nuanced differences in phrasing or meaning that are common in natural language tasks.
- Lack of subjectivity: Many real-world applications of LLMs involve tasks where there is no “one right answer.” For example, writing a creative story or responding to a complex question can have multiple equally valid outcomes, and traditional metrics fail to capture this variability.
LLM Comparator research [https://arxiv.org/abs/2402.10524] highlights that while these metrics are computationally efficient, they fail to capture human preferences and deeper qualities like creativity, fluency, or informativeness—qualities that are often critical in AI applications. Developers need a more nuanced, real-world approach to model evaluation.
2. What is Head-to-Head Evaluation and Why Does it Work?
Head-to-head evaluation is a more direct and reliable way to compare AI models. Instead of comparing each model’s output to a static reference, head-to-head evaluations involve pitting two models’ outputs against one another for the same prompt. An evaluator—either human or LLM-based—then selects which of the two outputs is better based on task-specific criteria, like fluency, relevance, or correctness.
Why head-to-head comparisons are effective:
- Reflecting human judgment: Research for Chatbot Arena [https://arxiv.org/abs/2403.04132] has shown that pairwise, head-to-head comparisons align closely with human judgment. In tasks where the quality of responses is subjective (e.g., conversational agents), human evaluators consistently favor direct comparisons over isolated metric-based evaluations.
- Mirroring real-world decision-making: Many tasks in natural language generation require subjective decisions—two outputs might both be correct, but one may be more fluent, clearer, or more creative. Head-to-head comparisons mimic how humans would make these judgments in real-world scenarios, offering a more realistic and nuanced evaluation.
How AutoArena implements head-to-head evaluation: AutoArena automates this process by either using LLMs as evaluators or allowing human judges to manually evaluate outputs. LLM-based evaluators, such as GPT-4 or Cohere Command R, can automatically determine which model’s output is preferable, replicating human decision-making at scale.
Example: Suppose two models are tasked with summarizing an article. Both summaries are reasonable but differ in clarity and length. AutoArena’s head-to-head evaluation compares the two outputs directly, asking an LLM evaluator or human judge to pick the better one. The winning model’s score improves, while the losing model’s score decreases.
3. How Elo Scoring Transforms Head-to-Head Comparisons into Rankings
Elo scoring provides the foundation for ranking models based on their head-to-head comparisons in AutoArena. Originally designed for ranking chess players, Elo scoring adjusts dynamically as new results come in, allowing for a more nuanced and reliable reflection of each model’s performance.
How Elo Works in AutoArena
- Starting Scores: All models begin with a base Elo score of 1000. When two models are compared, the winner’s score increases and the loser’s score decreases. The amount of change depends on the relative scores of the two models—upsets (when a lower-ranked model beats a higher-ranked one) lead to larger score changes.
- Evolving Rankings: As more comparisons are made, the Elo system recalculates rankings in real time. This allows for an evolving, dynamic leaderboard that reflects current model performance without needing to re-evaluate all previous matchups. Over time, models’ rankings stabilize as their Elo scores are informed by numerous comparisons.
- Confidence Intervals: Elo scores in AutoArena are accompanied by confidence intervals, providing an estimate of how reliable each model’s score is. As more data points are collected, these intervals narrow, giving developers more confidence in the rankings.
The Science Behind Elo Scoring
The Elo system’s mathematical framework allows it to weigh comparisons based on the difficulty of each match, producing more accurate and trustworthy rankings than simple win-loss records. As demonstrated in research from LLM Comparator [https://arxiv.org/abs/2402.10524], Elo scoring aggregates many comparisons to deliver a holistic performance metric, capturing both individual match results and the context of those results. This makes it ideal for AI model evaluation, where models often face varying levels of competition.
Why Elo is Ideal for AI Model Testing
- Adaptability: Elo scores update dynamically, allowing developers to test new models and configurations without needing to rerun all previous comparisons.
- Transparency: Each score reflects not just a model’s win rate but also the quality of its victories, giving more granular insights into which models are truly excelling.
By using Elo scoring, AutoArena generates accurate, real-time leaderboards that allow developers to track model performance efficiently and confidently.
4. The Power of Juries: Using Multiple LLMs to Evaluate Models
In addition to head-to-head comparisons, AutoArena employs a jury of LLMs to further enhance evaluation accuracy. Rather than relying on a single judge model (like GPT-4) to evaluate outputs, AutoArena can pool judgments from multiple models, forming a Panel of LLM Evaluators (PoLL). This strategy helps to reduce bias and provide a more balanced evaluation.
Why Juries Outperform Single Judges
According to the research in Replacing Judges with Juries [https://arxiv.org/abs/2404.18796], relying on a single model for evaluations can introduce intra-model bias, where the judge model might favor outputs that align with its own language style or reasoning. By using a jury of LLMs from different families (e.g., GPT, Cohere Command R, and Claude), AutoArena mitigates this bias and offers more trustworthy evaluations.
- Diverse Perspectives: Each model in the jury contributes its unique evaluation perspective, leading to a more well-rounded judgment. This reduces the risk of overfitting evaluations to a single model’s idiosyncrasies.
- Cost-Efficient: Smaller models are often cheaper and faster to run than large models like GPT-4, and using a jury of smaller models can save both time and resources while still delivering more reliable results than a single large model.
How AutoArena Leverages Multiple Judges
- When evaluating two model outputs head-to-head, AutoArena doesn’t rely on just one decision—it uses votes from multiple LLM judges. The final evaluation is determined by pooling these votes, with the majority decision informing the final ranking.
- This process is similar to how human juries reduce individual biases by averaging out the preferences of multiple people, providing a more objective judgment.
By incorporating multiple LLM evaluators, AutoArena ensures more robust, unbiased, and reliable rankings—especially in tasks that require nuanced judgments.
5. From Comparisons to Leaderboards: How AutoArena Builds Trustworthy Rankings
The combination of head-to-head comparisons and Elo scoring produces a dynamic leaderboard of AI system variations in AutoArena. This leaderboard evolves as models are compared, providing developers with an up-to-date ranking of model performance across tasks.
How the Leaderboard is Generated
- Each time a model or system variant competes in a head-to-head evaluation, its Elo score is updated, adjusting its position on the leaderboard. Over time, as more comparisons are made, models settle into rankings that reflect their true performance across a variety of prompts and tasks.
- The confidence intervals provided alongside Elo scores help indicate how stable each model’s ranking is, giving developers more insight into whether a model’s position is firmly established or might change as more data comes in.
Why These Rankings Are Trustworthy
AutoArena’s ranking system is scientifically validated through studies like LLM Comparator [https://arxiv.org/abs/2402.10524] and the PoLL method [https://arxiv.org/abs/2404.18796], which demonstrate that head-to-head comparisons combined with Elo scoring correlate closely with human judgments. By using real-time, evolving comparisons instead of static benchmarks, AutoArena ensures that rankings stay relevant and accurate even as new models and configurations are introduced.
- Dynamic Updating: The leaderboard updates automatically as new comparisons are made, meaning developers can continuously assess the performance of new models or updates.
- Transparent Metrics: The Elo score provides a clear, interpretable metric for ranking, while the confidence intervals give additional transparency into how reliable those rankings are.
This real-time, scientifically-backed leaderboard helps developers make informed decisions about which models to prioritize, fine-tune, or deploy.
6. Using AutoArena to Improve AI Model Development
AutoArena’s evaluations offer developers a powerful tool for refining and optimizing their AI models. Here’s how you can use AutoArena’s results to improve your development process:
Faster Iteration and Testing
- Quickly test new configurations: AutoArena allows you to compare models across different versions, prompt setups, or fine-tuned configurations in real time. Instead of waiting for long manual evaluations, developers can see immediate results on the leaderboard.
- Shorten the feedback loop: The head-to-head evaluations give you quick, clear insights into which versions of a model perform better, enabling faster iteration and more informed decision-making.
Data-Driven Model Selection
- Objective comparison: AutoArena’s leaderboard helps you select the best model objectively based on Elo scores, eliminating guesswork. Developers can confidently deploy the top-performing models knowing they have been rigorously tested against others.
- Prioritize model improvements: By examining which models consistently win or lose head-to-head comparisons, developers can identify areas for improvement and focus on enhancing weaker aspects of their models.
Cost-Efficient Evaluations
- Use LLMs as cost-effective evaluators: Instead of relying solely on expensive human judgments, AutoArena allows you to use LLM-based juries, which provide reliable evaluations at a fraction of the cost.
- Avoid unnecessary retraining: With AutoArena’s dynamic ranking system, developers can avoid retraining or optimizing models that already perform well, allowing resources to be allocated more efficiently.
By integrating AutoArena into your AI development pipeline, you can optimize models more quickly and confidently, delivering better results with less effort.
7. Why AutoArena’s Approach is Scientifically Backed and Effective
AutoArena’s approach to AI model evaluation is grounded in rigorous scientific methodologies, making it a reliable and effective tool for developers. Let’s break down why the combination of head-to-head evaluations, Elo scoring, and LLM-based juries offers a superior evaluation process compared to traditional methods.
Research-Backed Validation
- Head-to-head evaluations have been shown to align more closely with human preferences than traditional metrics like BLEU or ROUGE. According to the research in Chatbot Arena [https://arxiv.org/abs/2403.04132], pairwise comparisons, where two outputs are judged against each other, consistently lead to more accurate rankings. This approach mirrors how people make decisions in real-world applications, making it a more realistic measure of performance.
- Elo scoring, used extensively in ranking systems like chess, adds a dynamic and reliable way to rank models based on direct comparisons. Findings in the LLM Comparator paper [https://arxiv.org/abs/2402.10524] validate that Elo-based rankings aggregate multiple evaluations into a trustworthy score, giving a global ranking of model performance that is both flexible and accurate.
- LLM juries offer an additional layer of robustness to evaluations. Research in Replacing Judges with Juries [https://arxiv.org/abs/2404.18796] proves that using multiple, smaller LLMs to evaluate outputs reduces bias and increases accuracy compared to relying on a single large model. This diversity of perspectives enhances the reliability of the rankings by capturing a wider range of evaluations.
Why AutoArena’s Approach is Effective for Developers
- Continuous improvement: Because AutoArena provides real-time feedback through dynamic leaderboards, developers can make informed decisions about which models to improve and iterate on. This feedback loop shortens development cycles, allowing teams to experiment with different configurations and promptly see the results.
- Accurate model selection: By using scientifically-backed techniques to generate its rankings, AutoArena ensures that the model ranked highest on its leaderboard is genuinely the best performer. This helps developers avoid the pitfalls of relying on subjective or outdated metrics, leading to more confident decision-making when deploying models.
- Scalable and cost-effective: AutoArena’s ability to use LLMs as evaluators makes it scalable and more cost-effective than relying solely on human evaluations. This opens the door for organizations to conduct large-scale model comparisons without breaking the budget.
By leveraging proven methods from academic research, AutoArena offers a trustworthy and scalable approach to model evaluation, ensuring that developers can test models faster, more accurately, and at a lower cost.
AutoArena is the Best Choice for AI Model Evaluation
As AI continues to evolve, so too must our methods for evaluating model performance. Traditional metrics are no longer sufficient for capturing the full spectrum of a model’s capabilities, especially in areas like text generation, where there’s often no single “correct” answer. AutoArena’s combination of head-to-head evaluations, Elo scoring, and LLM-based juries represents a modern, scientifically validated approach to AI model testing.
With AutoArena, developers can:
- Evaluate models faster through automated, dynamic head-to-head comparisons.
- Generate accurate rankings using proven methods like Elo scoring.
- Leverage cost-efficient LLM juries for unbiased, reliable evaluations.
- Improve models iteratively with real-time feedback from a dynamic leaderboard.
By choosing AutoArena, developers can streamline their model testing processes, making data-driven decisions with confidence. With a scientifically-backed system that evolves alongside your models, AutoArena ensures that you always have the best tools to optimize your generative AI systems.
Ready to experience faster, more accurate model evaluations? Try AutoArena today and see how it can transform your AI development process. For step-by-step instructions to use the open-source package, check out our Getting Started with AutoArena guide.