Read Part 1: Validating OpenAI GPT Model Performance
Prompt engineering is a special term from the NLP industry to describe the formulation of better questions for LLMs (large language models) to get better answers. In other words, it is the art of effective prompt design.
If you think about it, we all perform prompt engineering throughout our daily lives. Some people vocalize their curiosities out loud as questions. Other people repeatedly Google search for information until they find answers. Persistent people, especially children, keep asking “Why? Why? But why?” or change their original question until they have a satisfactory answer.
For LLMs, prompt engineering works in a very similar way. Users expect LLMs to produce an output based on a given input, that is, the prompt. When an output isn’t to a user’s liking, they might modify their prompts to hopefully get better results. Prompt engineering is the key that unlocks LLMs to let them produce output at their maximum potential. It is the tiny rudder that steers a 400 billion-parameter ship in the right direction.
From the perspective of a machine learning engineer at Kolena, this article offers a guide toward evaluating prompt effectiveness. We’ll use OpenAI’s GPT-3.5 Turbo model to continue exploring the text summarization problem for news articles.
Necessary Next Steps
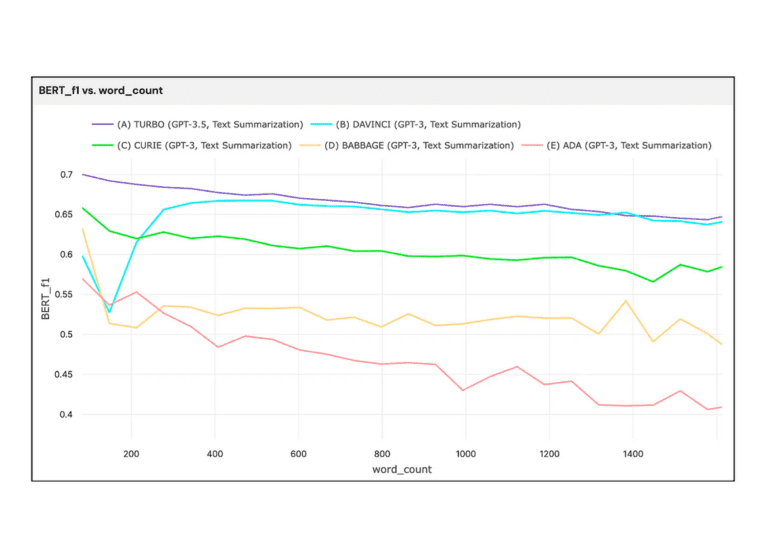
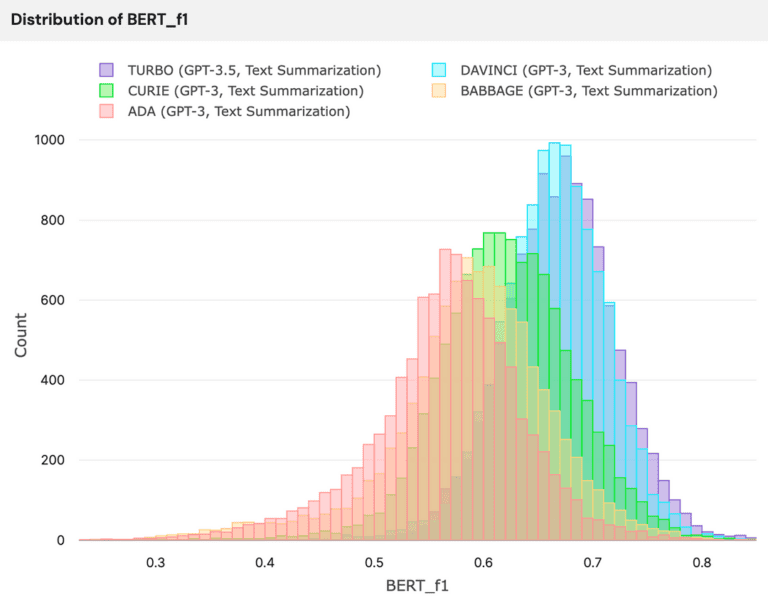
The previous blog post explored a text summarization problem, namely, by using generative AI to summarize news articles. We used the CNN-DailyMail dataset (11,490 news articles, each with human-made ground truth summaries) and compared the performance of five different GPT models. In the end, Turbo (gpt-3.5-turbo) generated the best summaries and yielded the highest overall performance at the lowest cost.
Our next step is to determine whether different prompts result in dramatic performance differences and quantitatively evaluate how well Turbo obeys its given prompts.
Evaluation Metrics
We want to avoid qualitative performance evaluations because the summaries we declare to be “better” might not be consistent with another person’s opinions. Qualitative comparisons always introduce the issue of human bias and subjectivity. Instead, we will once again focus on quantitative performance evaluations.
The previous blog post already defined text-based performance metrics such as BERT_rec (BERTScore’s recall), wc_inf (inference word count), and ROUGE_L. Here, we’ll add three new metrics:
- METEOR: A better BLEU, claimed to have a higher correlation with human judgment (0 to 1).
- formality: A score indicating the level of informality or formality in a text (0 to 1).
- pii_count: A metric that counts the proper nouns or personal data within a text.
We can use these metrics to identify poor performance when a model generates lengthy or informal summaries. In general, generated summaries should remain short and preserve the formal tone of the original news articles.
The Prompts
We used eight prompts against the Turbo model for eight different sets of generated summaries. We outline them below with a one/two word alias (bolded), followed by the original prompt:

Performance Differences
To see which prompts are better for generating summaries based on text similarity, we can list out the top five prompts per metric by order of performance (best first):

The top five prompts for BERT_rec, ROUGE_L, and METEOR consistently include the words DetailedV2, Detailed, Uppercase, and Basic. Without going into too much detail, DetailedV2 performs better than Basic by 0.4% for BERT_rec, 4% for ROUGE_L, and 3% for METEOR.

Distribution of ROUGE_L: DetailedV2 > Basic
From the plot above, we can observe that the blue histogram has higher values than the purple histogram. This indicates that DetailedV2 performs at a higher level than Basic for ROUGE_L, which is an improvement. In general, these four prompts (DetailedV2, Detailed, Uppercase, and Basic) outperform other prompts such as No PII or Point Form against text similarity metrics. This is not surprising as No PII and Point Form are prompts with different output requirements that may cause a decline in the amount of retained information within generated summaries.

Distribution of ROUGE_L: 60 Words > DetailedV2
An interesting observation is that 60 Words is the best prompt for yielding the greatest ROUGE_L score, even though 60 Words is not within the top five prompts for other text similarity metrics. We can see this in the purple bars from the 60 Words distribution peeking out to the right of the blue distribution. If you value the ROUGE_L metric the most out of all the other metrics, you would want to use 60 Words as your prompt, which might not be the most obvious choice when DetailedV2 appears to perform well consistently. This is why prompt engineering is important.
Adherence to Prompts
To measure how well GPT Turbo adheres to our prompts, we will look into three different avenues: PII counts, word counts, and formality.
How well does GPT Turbo adhere to requests that limit PII?
For some GPT users, a potential requirement in generated outputs is to avoid PII. Many people value the security and privacy of their personal information, and some businesses might need to preserve data anonymity — there could be legal requirements to do so, as well.
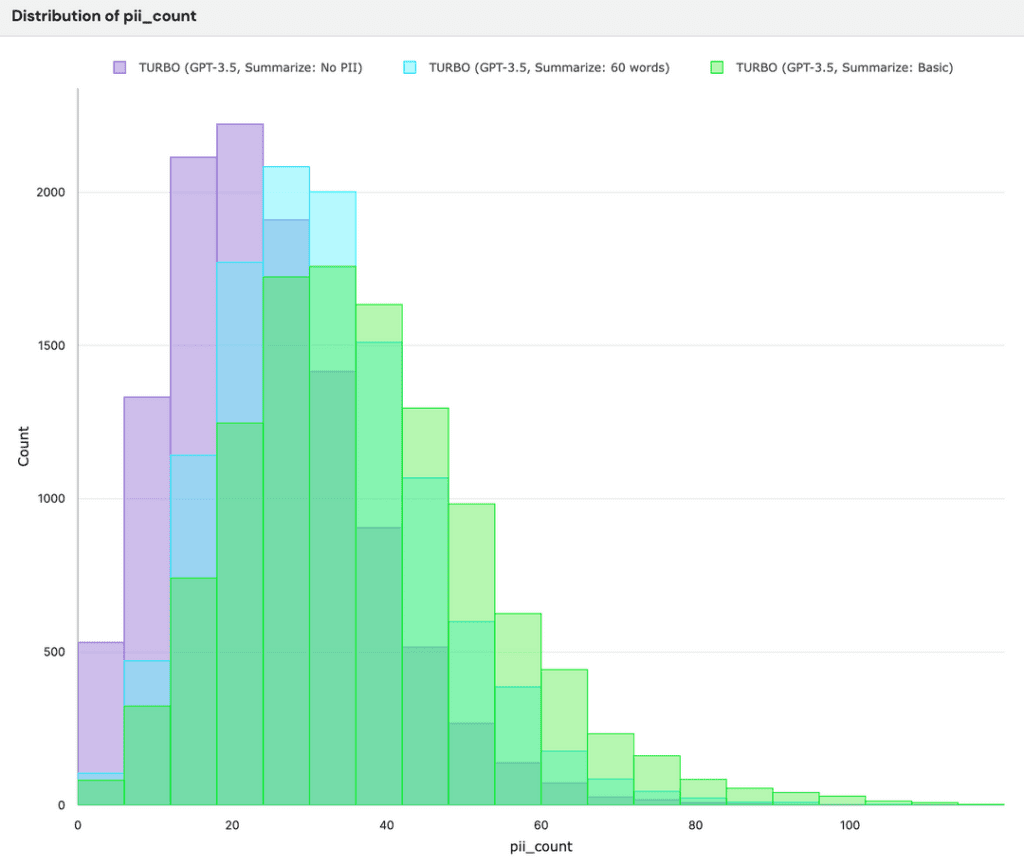
Let’s see how well Turbo adheres to No PII, which states, “Do not use any proper nouns”, and compare it to Basic and 60 Words as a baseline. We should expect to see zero PIIs coming from No PII, or at the very least, something significantly lower in number compared to the baselines.

Distribution of PII counts: Basic > 60 Words > No PII
From the above, the Turbo model does reduce the number of PIIs within generated summaries for No PII (purple), but it’s far from averaging zero PIIs. Although most generated summaries have a non-zero amount of PIIs, summaries from No PII average around ten fewer PIIs in comparison to the other prompts.
Let’s look at an example and compare a generated summary of No PII and 60 Words with the provided ground truth summary:
Ground Truth: Welsh Wizard Gareth Bale opened the scoring in Sunday’s stunning win. Real Madrid put nine goals past Granada to keep pressure on Barcelona. Bale treated himself to a BBQ in the Spanish sun following victory. Cristiano Ronaldo scored five goals in the sensational team performance.
No PII: Gareth Bale scored a goal for Real Madrid in their 9–1 victory against Granada. He also tweeted about the win and had a BBQ later that evening. Cristiano Ronaldo scored five goals in the same match. Real Madrid bounced back from their previous defeat.
60 Words: Gareth Bale celebrated Real Madrid’s 9–1 victory over Granada with a BBQ, after opening the scoring in the game. Cristiano Ronaldo scored five goals in the game, including an eight-minute hat-trick, to keep the pressure on La Liga leaders Barcelona. The win came after Real Madrid’s defeat to Barcelona in El Clasico.
The summary from No PII has 16 PIIs, whereas the summary from 60 Words has 27 PIIs. This makes sense as it is very hard to write a summary for an article about Bale and Ronaldo without mentioning their names.
In fact, creating a straightforward summary with zero proper nouns is very hard, even for the best creative writers. As a challenge for yourself, try to properly describe Ronaldo and Bale without using any names or places. GPT Turbo decided to create a summary with proper nouns to preserve the usability of the generated summary, so Turbo does not adhere to completely avoiding proper nouns, but it certainly makes an effort to reduce the usage of PIIs.
How well does GPT adhere to requests with a word count limit?
Word count restrictions are important in prompts to have some control over the number of potential tokens used and to meet custom requirements. When a prompt says to use around 60 words (No PII, 60 Words), we should expect the average word count of output to be 60 words. For Detailed, which has a word range, we wouldn’t expect summaries to exceed or fall short of that range.

Distribution of summary word counts: Point Form > Basic > Detailed > 60 Words > No PII
This plot reveals that Turbo generates shorter summaries when prompts define a targeted word count of 60 words (No PII in red and 60 Words in yellow). However, most of the generated summaries have a length above 60, ranging between 80 to 100 words. This is not ideal, but it isn’t too far off target. Between No PII and 60 Words, No PII follows the prompt’s instructions much better.
For Detailed, Turbo consistently produces summaries between 75 and 125 words. Since the average word count for the ground truth summaries is about 55 words, the expected range for most generated summaries should be 50 to 100 words. For longer articles and longer ground truths, the expected range for summaries shouldn’t stretch to 200 words. It seems like Turbo consistently hits a word count around the upper limit of the defined ranges. Perhaps it wants to produce a summary of the “best” quality, and the way to achieve that is by using more words when possible.
Side note: When people write point form notes, they are typically brief and succinct, so it is surprising that Point Form leads Turbo to create lengthy summaries averaging 120 words. While we might expect brevity, Turbo might not have understood that implicit assumption. Sometimes, you need to add extra detail when designing your prompts.
When it comes to word counts, GPT Turbo does acknowledge the demands set in the prompts, but it does not completely adhere to them. We can only speculate that Turbo makes a choice to use more words instead of settling for a shorter summary of “worse” quality. The greater the number of words a generated summary has, the greater the potential for that summary to contain all of the article’s important information.
How well does GPT respond to requests to make things professional?
Professionalism is a hard thing to measure, so we use formality scores to gauge if a text is more formal/professional than another.
By overall formality score, the three best prompts (in order) are No PII, 60 Words, and Basic, but none of them ask for a “professionally” written summary. Let’s use Basic and Uppercase as baselines for Professional and DetailedV2.

Distribution of formality scores: Basic > DetailedV2 > Professional > Uppercase
From this histogram, we see that there is no drastic difference between the formality of the summaries generated from Basic, DetailedV2, and Professional. Basic, the simplest and least decorated prompt, has the greatest number of very professional/formal summaries. Interestingly, Uppercase seems to yield the least formal summaries. Could it be that caps-locking demands against GPT negatively impacts performance? Does GPT have artificial feelings now?
Sometimes, the simplest prompts yield the best results. In this case, it is evident that asking GPT Turbo to write “professionally” does not contribute to formality scores.
Learnings
For GPT’s Turbo model, different prompts do result in slight performance differences. In terms of our problem, the differences between text similarity metrics are not as apparent as our custom metrics. With different LLMs of different sizes, performance deltas for text similarity metrics could be more obvious, but also adhere to prompts in unique ways.
In terms of obedience, Turbo clearly makes an effort to follow each prompt’s specific instructions for explicit word count ranges and minimized PIIs. Unfortunately, it does not distinctively differ in performance or behavior when prompts ask for a more professional or formal style of writing. Maybe GPT’s default setting is to always remain professional.
Concluding Thoughts
Engineering a thoughtful prompt works in a similar way to fine-tuning a model. While the subject of prompt engineering continues to grow and evolve, it is important to understand how well a prompt directs an LLM beyond just qualitative checks. When prompts lack detailed specification, or when output requirements suddenly change, qualitative testing won’t scale well.
To understand the value of your prompts across an entire dataset, it’s important to tie in quantitative testing as much as possible. Our approach to quantitatively evaluate prompts against the Turbo model for the text summarization task includes these steps:

With these steps, anyone can automatically measure how well their LLMs follow prompt specifications. Furthermore, these steps outline a testing paradigm where qualitative analysis slowly loses relevance. Those who desire automation and scalability with the least amount of human effort should shift towards quantitative testing practices.
Stay tuned for future posts where we discuss quantitative testing to surface the hidden and different behaviors of LLMs! Spoiler alert: there may be scenarios where performance unexpectedly drops.
If you are hungry for more details about this blog post, here’s a link to a CSV export from Kolena showing all the aggregate performance metrics for each of the eight prompts (and so much more).
All images are screenshots taken from Kolena unless otherwise indicated. Note that similar plots can be manually generated in common frameworks such as Matplotlib.