In today’s data-driven world, businesses are increasingly turning to AI to streamline complex analytical workflows. From finance to data science, AI tools can automate the retrieval of relevant information and execute time-consuming calculations with remarkable efficiency. Among these tools, RAG (Retrieval-Augmented Generation) has garnered attention for its ability to combine retrieval and generative capabilities, delivering precise and context-aware outputs. However, while RAG has proven useful for many applications, it may fall short when applied to complex analytical workflows.
In this post, we’ll explore the shortcomings of using RAG for analytical workflows, and contrast it with Kolena’s Restructured, focusing on how they handle common challenges, and why Restructured may be the better choice for businesses that rely on in-depth data analysis.
The Potential (and Limitations) of RAG
RAG is a relatively new AI architecture that integrates retrieval systems with generative models. By combining the two, RAG can dynamically pull information from large datasets and synthesize it into coherent and factually informed responses. This hybrid approach is exciting because it allows for on-the-fly content generation based on real-time data retrieval, which is especially valuable for businesses that deal with vast amounts of information.
For example, in a customer service scenario, RAG can quickly retrieve relevant documents from a knowledge base and generate an accurate response to a user query. This ability to merge retrieval with content generation leads to more informed outputs, making RAG a valuable tool for quick, fact-based tasks.
However, RAG’s strengths also reveal its limitations, especially when applied to more complex workflows that require more than just retrieving and generating text. Analytical workflows often involve multiple stages, continuous iteration, and the application of domain-specific knowledge—areas where RAG tends to fall short.
Three Example Workflows: Restructured vs. RAG
To better illustrate where these limitations arise, let’s compare how Restructured and RAG perform in three common analytical workflows:
1. Iterative, Multi-Step Workflows
Most analytical workflows are not a one-and-done operation. They require multiple steps, each building on the previous one. RAG operates in a query-by-query fashion, generating responses based on the input it receives. But it lacks the mechanism to handle iterative workflows, where the user needs to refine data, perform calculations, and update insights over multiple stages. Without this iterative capability, users are left to manually perform these steps outside the AI tool, reducing efficiency and increasing the likelihood of errors.
Restructured, on the other hand, is built around iteratively solving a problem. The Task Planner, for instance, breaks a problem down into steps, executes complex extractions, and makes adjustments as needed, without having to restart from scratch. This is particularly useful for data analysts and financial professionals who need to continuously adjust inputs and re-run models to achieve optimal results.
Example (Restructured vs NotebookLM):
We uploaded mixed media files (PDFs and images) for various receipts for purchases in 2024. We then attempted to identify spend on Amazon during the preceding six months.
With NotebookLM, the chat interface first refused to answer due to ambiguity in how it interpreted the “past 6 months” as a phrase. After re-phrasing the question, the tool attempted to answer the question in a single shot, which left room for multiple errors:
- The “past 6 months” was interpreted as May 1, 2024 through November 1, 2024, despite this question being asked on October 24, 2024.
- The response included expenses from April, despite being outside of the desired timeframe.
- As a result, NotebookLM failed to correctly answer the question, instead overstating the expenditure.
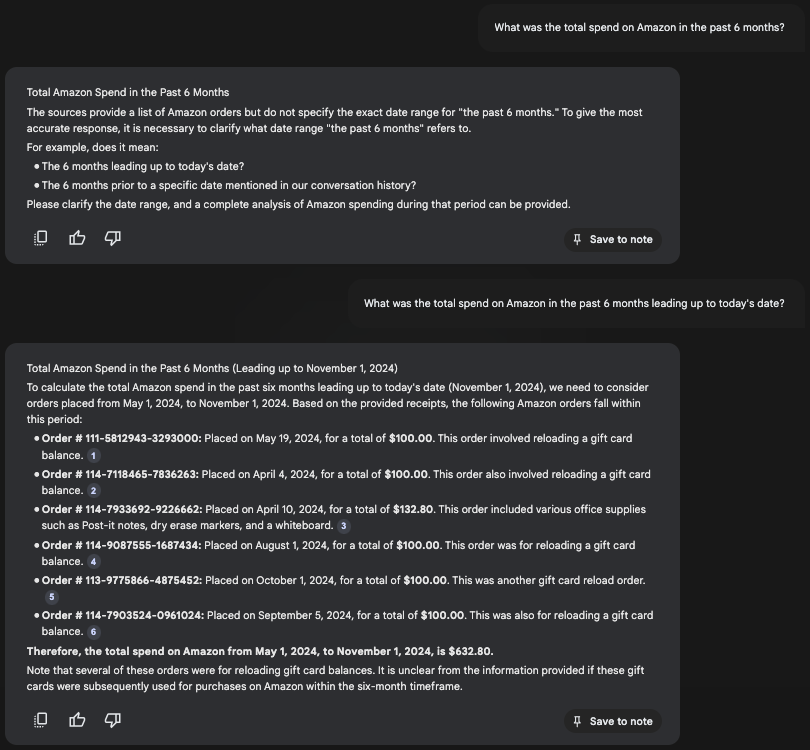
With Restructured, the tool first decomposed the problem into extracting the relevant information: the amount of the expenditure, the date of the transaction, and whether it was an Amazon expense or not. Afterwards, it filtered and aggregated the relevant values and came to the correct total of $400.
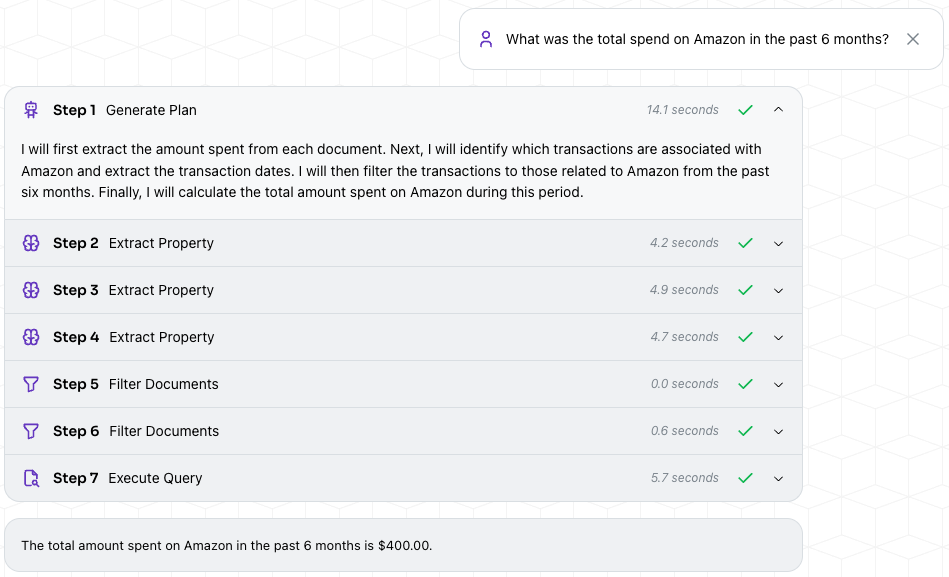
2. Large Number of Relevant Documents
When analyzing large datasets, the ability to accurately sift through and prioritize relevant documents is critical. RAG is effective at quickly retrieving relevant information, but when dealing with a high volume of documents, it can miss important details or fail to rank information in a way that’s most useful to the user.
In contrast, the iterative approach taken by Restructured allows for honing in on the relevant data, and fitting the relevant information into the context window. This allows for the processing of a larger scale of data, as well as more precision in the steps taken.
Example (Restructured vs NotebookLM):
We upload several years of AWS invoices with the goal of identifying where month-over-month EC2 spend increased the most.
NotebookLM (Google’s RAG tool) first fails to include all of the relevant documents in context, and then hallucinates while retrieving the spend values, leading to a confidently incorrect answer.
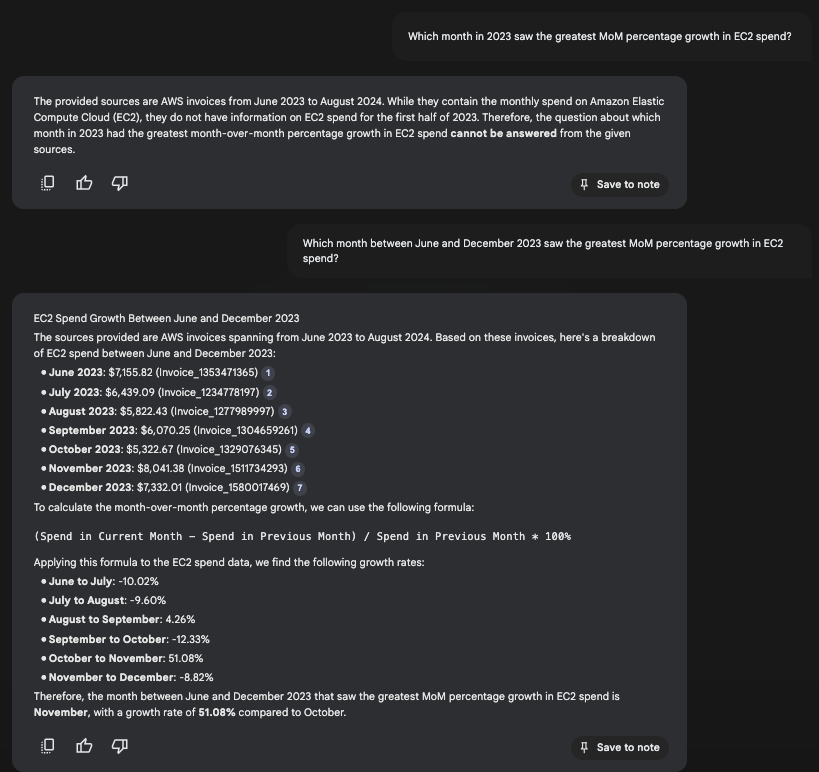
Restructured extracts the meaningful spend values and combines them to surface the correct answer, avoiding any concerns with a limited context window.
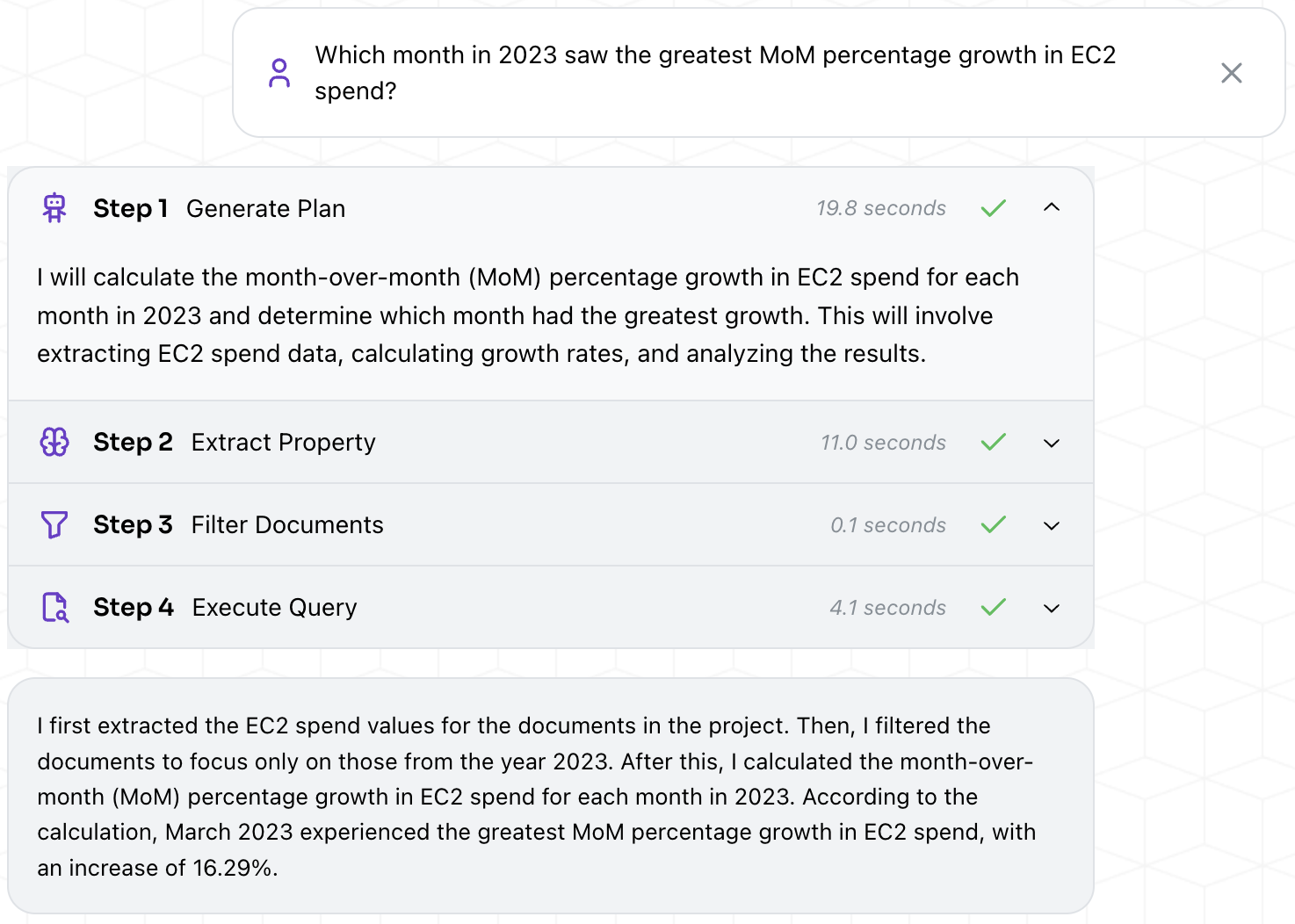
3. Contextual Equations
RAG may be able to retrieve relevant information, but it struggles with applying this knowledge contextually to solve domain-specific problems, especially those that involve complex calculations. For instance, in financial analysis, a user might need to calculate EBITDA (Earnings Before Interest, Taxes, Depreciation, and Amortization) based on specific input data. While RAG could retrieve a definition of EBITDA or generate an equation, it may not have the ability to perform the calculation in real-time using the user’s dataset.
Example (Restructured vs NotebookLM):
We attempt to compute EBITDA against Home Depot’s 2024 Q1 10-Q document, which does not include an explicit line item for EBITDA, but does contain the raw information necessary to construct a value.
With NotebookLM, the tool attempts to retrieve EBITDA, fails to locate it, and instead opts to provide a replacement metric, NOPAT.
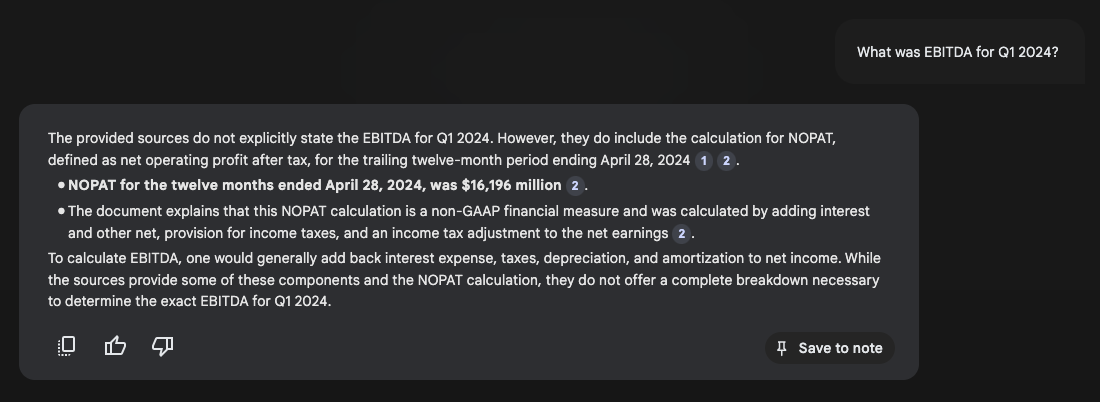
With Restructured, we are able to seed the knowledge base with an equation for EBITDA. As a result, the tool is able to retrieve the relevant line items and compute the correct EBITDA value from the 10-Q.

Conclusion
While RAG represents a significant advancement in AI-driven information retrieval, it has clear limitations when applied to complex, iterative analytical workflows. Businesses that rely on in-depth data analysis, continuous iteration, and domain-specific calculations need tools that go beyond retrieving documents or generating responses. Kolena’s Restructured offers a more robust solution, providing the precision, adaptability, and real-time processing capabilities necessary for today’s complex workflows.
As AI tools continue to evolve, the choice between RAG and Restructured depends on your specific needs. If you’re looking for quick, fact-based retrieval and content generation, RAG may suffice. But if your business demands detailed analysis, iterative processing, and dynamic calculations, Restructured stands out as the superior option.