

What Is Machine Learning Operations (MLOps)?
Machine Learning Operations (MLOps) refers to the practices, tools, and methodologies that enable organizations to streamline the development, deployment, and maintenance of machine learning models. It encompasses the entire lifecycle—from data preparation and model training to deployment and monitoring—aimed at automating and improving entire ML systems in production.
MLOps bridges the gap between the model development phase and the operational deployment stage, ensuring consistent and scalable deployment of ML models. This integration fosters collaboration among data scientists, engineers, and IT professionals, supporting a more agile and expedited transition from experimentation to production.

What Are the Principles of MLOps?
The following are key elements of any MLOps program.
Version Control
Version control is essential for managing changes to models, data sets, and code. It allows teams to track modifications, experiment with different versions, and roll back to previous states if necessary. This provides a historical record of the project’s evolution and facilitates collaboration.
Automation
Automation in MLOps streamlines repetitive tasks, such as data preprocessing, model training, testing, and deployment. By automating these processes, organizations can reduce human error, increase efficiency, and enable data scientists to focus on strategic tasks. Automation also supports the consistent execution of workflows, ensuring that ML models are deployed predictably and reliably.
Continuous Everything (Continuous X)
Continuous Everything, abbreviated as Continuous X, represents a holistic approach to integrating continuous practices—such as continuous integration (CI), continuous delivery (CD), and continuous training (CT)—into the machine learning lifecycle. This approach ensures that machine learning models are developed, tested, deployed, and updated in a seamless, automated manner.
Model Testing
Model testing involves the systematic evaluation of machine learning models to ensure they meet predefined standards of accuracy, performance, and reliability before deployment. It includes testing for concept, data, and model drift; unit testing of ML system components; integration tests; and performance tests. Effective model testing is crucial for identifying and rectifying issues early in the development process.
Model Governance
Governance encompasses policies, practices, and auditing models to ensure transparency, accountability, and regulatory compliance in machine learning systems. It emphasizes model fairness, explainability, and data privacy. MLOps governance frameworks help organizations manage model risk, maintain stakeholder trust, and comply with legal standards.
MLOps vs. DevOps: What Is the Difference?
MLOps and DevOps share the goal of automating and improving software deployment processes. However, MLOps focuses on challenges unique to machine learning, such as managing data sets, model versioning, and experimentation. DevOps deals more generally with software development cycles and operational efficiency.
MLOps also emphasizes continuous training and monitoring of models to adapt to new data, which is not a concern in traditional DevOps. The integration of MLOps into the DevOps framework enables more dynamic, data-driven applications that can evolve over time.
Key Components of an MLOps Pipeline
A typical MLOps pipeline includes the following components:
- Exploratory data analysis (EDA): EDA involves summarizing the main characteristics of data through visual and quantitative techniques. This initial step helps identify patterns, anomalies, potential biases, and the need for data cleaning or transformation. EDA is critical for defining the right approach for model training and feature engineering.
- Data preparation and feature engineering: This phase converts raw data into a clean dataset suitable for modeling. Tasks include handling missing values, encoding categorical variables, normalizing data, and creating features that enhance model performance. Effective feature engineering can significantly influence the accuracy and efficiency of the subsequent model training.
- Model training and tuning: In this stage, various machine learning algorithms are applied to the prepared data to build models. Model tuning involves adjusting hyperparameters to optimize performance, often using techniques like grid search or random search. The goal is to develop a robust model that generalizes well to new, unseen data.
- Model review and governance: Once a model is developed, it undergoes a review process to ensure it meets the required standards of performance and ethics. Governance involves setting up policies for model audits, compliance checks, and ethical reviews to ensure models perform responsibly in production.
- Model inference and serving: Model inference involves applying the trained model to new data to make predictions. Serving is the process of deploying the model to a production environment where it can respond to real-time or batch data requests. This step requires robust infrastructure to handle the load and ensure low latency responses.
- Model monitoring: After deployment, continuous monitoring of the model is essential to track its performance and detect issues like drift or degradation over time. Monitoring tools help in understanding when a model needs retraining or tweaking to maintain its accuracy and relevance.
- Automated model retraining: Models may degrade in performance as data evolves. Automated retraining involves periodically updating the model with new data, which helps maintain its efficacy. Automation of this process ensures that the model stays relevant and performs optimally without manual intervention.
Key Benefits of MLOps
The MLOps approach offers several advantages.
Faster Time to Market
MLOps accelerates the machine learning lifecycle, enabling quicker deployment of models into production. Faster time to market means that organizations can respond to changes and opportunities sooner.
Improved Productivity
By automating routine tasks and streamlining collaboration, MLOps boosts the productivity of data science and machine learning engineering teams. It allows data scientists to concentrate on model development rather than deployment intricacies, and makes it easier for machine learning and DevOps engineers to deploy models to production.
Efficient Model Deployment
MLOps ensures the efficient deployment of machine learning models, enabling consistent performance and scalability. Automated pipelines facilitate the smooth transition of models from development to production, minimizing downtime and errors. MLOps also supports dynamically allocating resources based on demand, optimizing costs and improving performance and availability.
What Are MLOps Tools?
MLOps tools are a critical part of an MLOps pipeline, which automate various stages from development to deployment and monitoring of machine learning models. Here’s a breakdown of the main types of MLOps tools:
- Data management and versioning tools: These tools manage datasets and model artifacts, ensuring that all data versions are tracked and reproducible. This is important for maintaining consistency across experiments and providing audit trails.
- Workflow automation tools: Automation tools streamline the entire machine learning pipeline, from data preparation to model training. They help standardize processes, reduce manual tasks, and make workflows scalable and reproducible.
- Model testing tools: Before deploying models into production, it’s critical to rigorously test them to ensure they meet predefined performance benchmarks and business standards. These tools facilitate various tests, including testing for drift, unit tests, integration tests, and stress tests, to ensure model robustness under real-life conditions.
- Model deployment tools: These tools manage the deployment of machine learning models into production environments. They handle tasks such as packaging, scaling, and versioning of models to ensure smooth and efficient rollout.
- Monitoring and performance management tools: After deployment, these tools continuously monitor the performance and health of models. They track metrics, detect anomalies, data drifts, and performance degradations that could affect model accuracy and reliability.
- Collaboration tools: Crucial for team-based machine learning projects, these tools facilitate better collaboration among data scientists, engineers, and other stakeholders. They help manage code, models, and experiments, allowing teams to work effectively together.
Understanding MLOps Maturity Levels
Organizations can be classified as achieving different maturity levels depending on their MLOps capabilities.
MLOps Level 0: Manual Processes
At Level 0, organizations manually manage machine learning workflows, from data handling to model deployment. This approach is labor-intensive and prone to errors, resulting in slow development cycles and challenges in maintaining model quality.
Moving beyond manual processes is essential for scale and efficiency. Organizations at this level should aim to automate data preprocessing and experiment with version control.
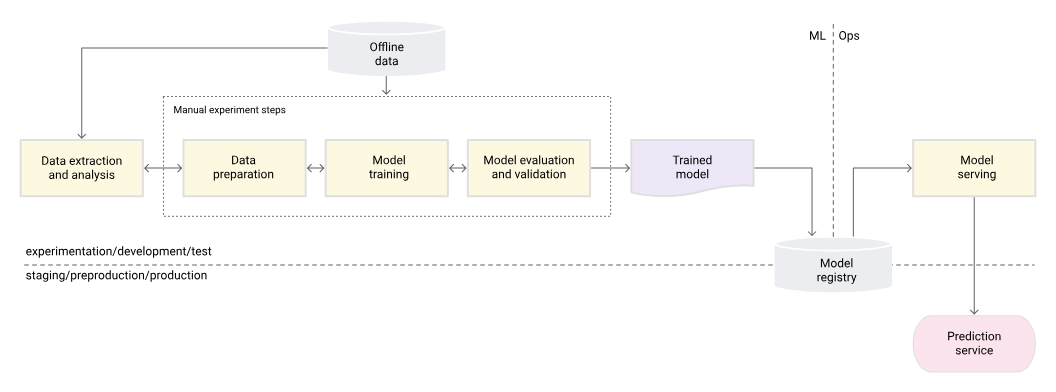
Source for this and the following images: Google Cloud
MLOps Level 1: Machine Learning Pipeline Automation
At Level 1, organizations begin automating the machine learning pipeline, introducing tools for continuous integration and delivery. This reduces manual intervention and improves repeatability and reliability.
Automation at this level focuses on streamlining specific aspects of the machine learning lifecycle, such as model training and validation, setting the stage for more sophisticated MLOps practices.

MLOps Level 2: Full CI/CD Pipeline Automation
At MLOps Level 2, organizations achieve full automation of the Continuous Integration (CI) and Continuous Delivery (CD) pipelines. This level is characterized by the integration of advanced automated processes that support the rapid development, testing, and deployment of machine learning models without human intervention. The CI/CD pipeline at this stage includes automated data validation, model training, model validation, and deployment processes that are continuously executed as new data and model updates are introduced.
The automation of CI/CD pipelines at Level 2 enables organizations to deploy models into production more frequently and with greater confidence. This is achieved by rigorous automated testing and validation stages that ensure each model meets performance standards before deployment. In addition, full automation of the pipeline facilitates seamless rollback capabilities, allowing teams to quickly revert to previous versions of models if a new deployment fails or does not perform as expected.
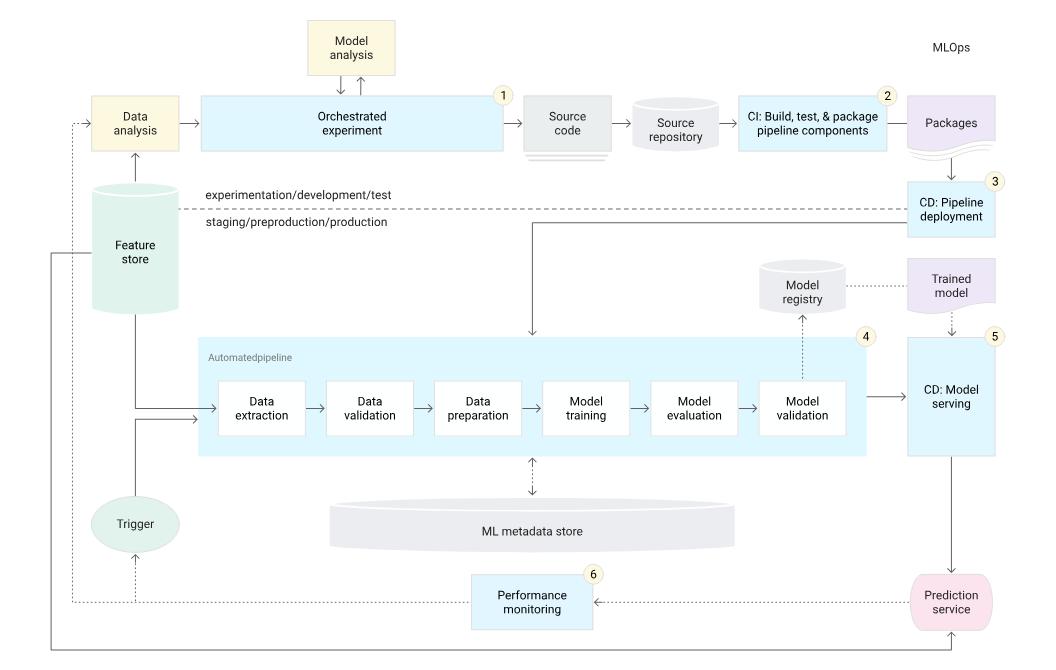
MLOps Challenges
Here are some of the common barriers to implementing MLOps in an organization.
Talent Shortage
There is a scarcity of skilled professionals who possess the expertise to implement and manage machine learning operations. This gap encompasses data science, software engineering, and operational skills, essential for bridging the divide between machine learning development and production environments.
Data Management
Effective data management is crucial for MLOps success, given the dependency of machine learning models on quality data. Challenges include data cleansing, standardization, ensuring access to relevant, up-to-date data, and data privacy concerns.
Security
Security in MLOps involves safeguarding data and models from unauthorized access and ensuring compliance with data protection regulations. Vulnerabilities can lead to breaches, compromising sensitive information and model integrity. Adopting comprehensive security measures like encryption, access control, and regular audits is essential to protect assets.
Inefficient Tools and Infrastructure
The lack of appropriate tools and infrastructure can result in inefficient workflows and scalability issues. Organizations must choose the right technologies that support automation, collaboration, and scalability. The MLOps platform should align with organizational needs and goals.
Best Practices for MLOps Adoption
Here are some measures that organizations can take to improve their MLOps implementation.
Efficient Data Labeling and Preparation
Efficient data labeling and preparation are crucial steps in the machine learning pipeline that significantly impact the quality of the model outputs.
Proper data labeling ensures that the training data is accurately annotated, providing a reliable basis for the model to learn from. This process often involves a mix of automated tools and human reviewers to balance speed and accuracy.
Data preparation involves cleaning, normalizing, and transforming raw data into a format suitable for model training. This step is essential to remove biases, handle missing values, and ensure consistency across data sets.
Robust data management strategies can streamline and improve these processes. For example, using advanced data annotation tools that leverage semi-supervised learning can reduce the need for manual labeling while maintaining high-quality data. Developing standardized data preprocessing pipelines that are reusable across multiple projects can save time and also significantly improve data quality.
Run Parallel Training Experiments
Parallel training experiments involve running multiple training sessions simultaneously with varying parameters, data subsets, or model architectures. This approach accelerates the model development process by allowing data scientists to quickly compare results and identify the most effective configurations.
By leveraging distributed computing resources, organizations can reduce the time required to train models, enabling rapid iteration and experimentation. This allows organizations to explore a wider parameter space without extending the overall development timeline. This enhances the robustness of machine learning models by exposing them to diverse conditions during training.
Automate Hyper-Parameter Optimization
Hyper-parameter optimization (HPO) is the process of automating the selection of the best hyper-parameters for a machine learning model. Hyper-parameters, unlike model parameters, are not learned from the data but are set prior to the training process and significantly affect model performance.
HPO techniques, such as grid search, random search, or Bayesian optimization, systematically explore a range of hyper-parameter values to find the combination that yields the best model performance. They enable more efficient model tuning, automating tasks that would otherwise require extensive manual trial and error.
Utilize Sanity Checks
Sanity checks are simple tests or procedures used to confirm that models are functioning as expected before and after deployment. These checks can include verifying that the model’s output range is correct, checking for the consistency of predictions across similar inputs, or ensuring that the model does not produce errors with new data.
Sanity checks are a quick and effective way to catch glaring issues that could indicate problems with the model’s logic, data processing, or integration with the production environment. They help maintain the integrity and performance of machine learning systems, allowing teams to address problems before they impact end-users.
Automate Model Deployment
Automated pipelines can handle the entire deployment process, including model testing, validation, and the deployment itself. By automating these steps, organizations can significantly reduce deployment time, minimize human error, and ensure that models are deployed in a consistent and reliable manner.
Automating model deployment also enables continuous delivery of machine learning models, allowing for frequent updates and improvements to be made with minimal disruption. It helps in scaling machine learning operations, allowing for the deployment of multiple models across different environments and platforms.
Implement Shadow Deployments
With shadow deployment, new machine learning models are deployed alongside existing ones without impacting the decision-making process. The new model’s predictions are made in parallel to the live model but are not used for real-world decisions.
This approach allows teams to monitor the performance of the new model in a live environment, comparing its outputs against those of the currently deployed model to identify discrepancies, performance issues, or improvements. It provides a safe testing ground for new models under real-world conditions without risking the integrity of the current system.
Continuously Monitor the Behaviour of Deployed Models
Continuous monitoring of deployed models is essential to ensure they perform as expected over time. This involves tracking key performance metrics, detecting drifts in data or model behavior, and identifying any anomalies that may indicate problems. Continuous monitoring allows for proactive maintenance of models, ensuring they remain accurate and reliable.
A thorough monitoring system enables teams to quickly respond to changes, whether by retraining models with new data, adjusting parameters, or deploying updates to address issues. This ensures that machine learning models continue to operate effectively in dynamic environments.
Building Your MLOps Pipeline with Kolena
Kolena offers an integrated MLOps platform designed to accelerate the deployment and management of machine learning models at scale. It simplifies complex ML workflows, from data prep to model production, with a focus on explainability, continuous testing, and monitoring for ML models.
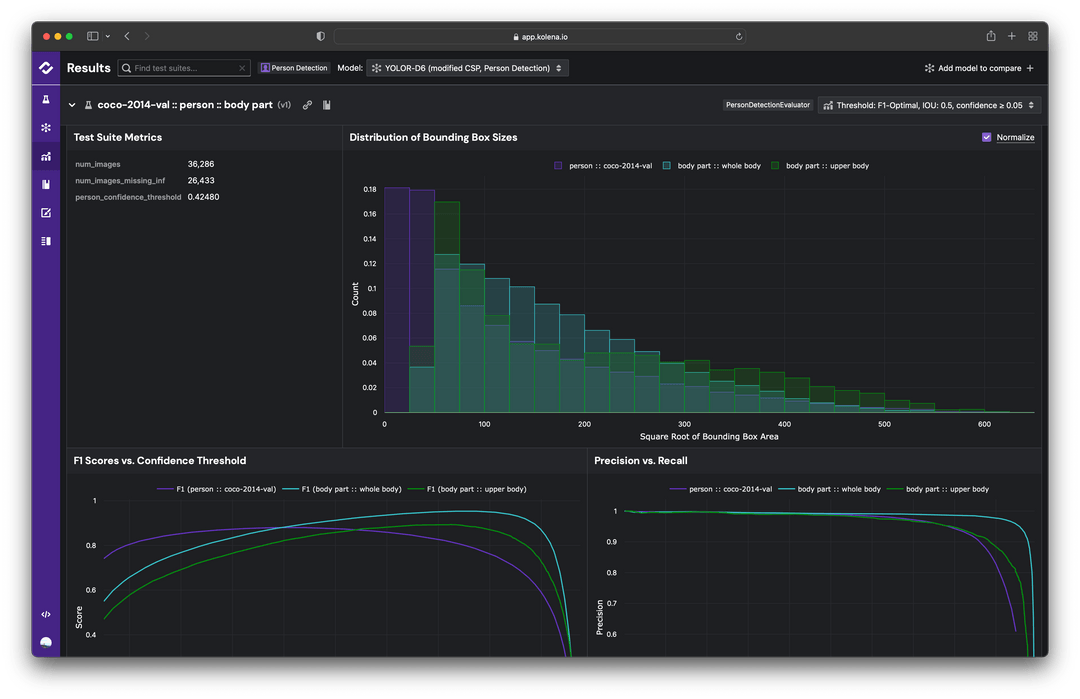
Kolena integrates seamlessly with existing data sources and infrastructure, providing a unified environment for end-to-end machine learning operations. Kolena’s automated pipelines and pre-built templates help streamline and automate ML workflows.
Learn more about Kolena for ML model validation, testing, and monitoring


