
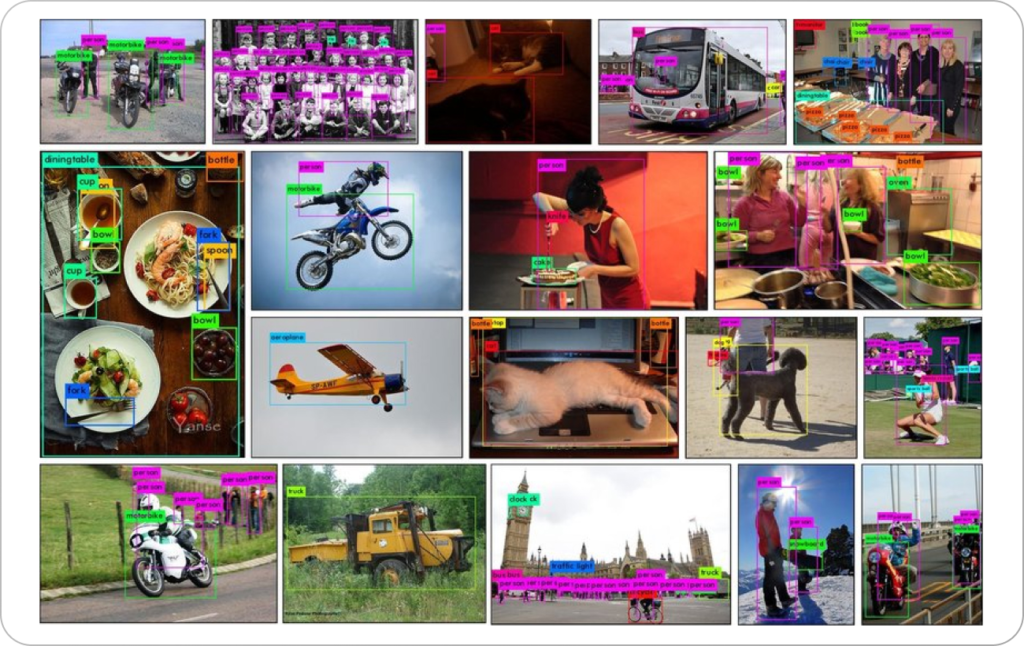
What Is MS COCO (Microsoft Common Objects in Context)?
MS COCO is a large-scale image dataset designed for object detection, segmentation, and captioning. Developed by Microsoft, it contains 330,000 images with millions of labeled objects across 80 categories. The dataset supports complex image understanding tasks, offering detailed annotations like object segmentation masks and bounding boxes. It also includes 5 captions describing each image.
MS COCO focuses on capturing objects in their natural context, helping to create machine learning models that can recognize and understand objects in diverse scenes. COCO is useful for computer vision projects, facilitating research and development by providing a rich, standardized dataset for training and benchmarking.
The image below illustrates how models trained on MS COCO are used to identify person keypoints (joints in the human body), a challenging computer vision task.

Source: MS COCO
Use Cases of the COCO Dataset
MS COCO can be used for the following use cases:
Object Detection and Recognition
The COCO dataset provides a diverse set of images and annotations, enabling the development of algorithms that can identify and locate multiple objects within a single image. It supports the creation of systems for surveillance, retail, and autonomous vehicles, where precise detection is critical.
The variety of objects and scenarios included in COCO enhances the robustness of detection models. It enables them to perform accurately across different environments, reducing the likelihood of errors due to unfamiliar contexts or rare objects.
Instance Segmentation
COCO’s detailed annotations help distinguish between individual instances of objects in an image. This fine-grained segmentation is useful for applications requiring precise outlines of objects.
The dataset offers varied scenery and object overlap scenarios. By training models on COCO’s dataset, developers can achieve higher accuracy in discriminating between closely situated objects and understanding complex scenes.
Semantic Segmentation
COCO can be used to teach a model to understand the scene at a pixel level, classifying each pixel into a category. This aspect is useful for applications like autonomous driving, where interpreting the road scene comprehensively is necessary for safe operation. The range of images and annotations aid in developing models capable of recognizing various objects and surfaces.
The dataset offers comprehensive coverage of different urban and rural settings. Semantic segmentation models are thus better equipped to handle the variability in real-world conditions.
Image Captioning
The dataset combines images and descriptive captions, enabling the development of models that can generate accurate and contextually relevant descriptions of images. This is useful in accessibility features for the visually impaired and content creation tools.
Training on COCO helps models understand the nuances of natural language and its association with visual elements, leading to more coherent and informative captions.
COCO Dataset Objects
Let’s look at some of the types of objects comprising the MS COCO dataset.
Info
The info section of the COCO dataset provides metadata about the dataset itself, including version details, description, and contributor information. This is useful for understanding the dataset’s scope and ensuring its proper use in research and application development.
This section also outlines the dataset’s structure and guidelines for usage, serving as a reference for developers and researchers. This ensures consistency in how the dataset is employed across various projects, facilitating its integration into different machine learning and computer vision tasks.
For example: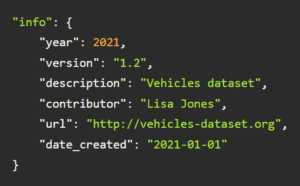
Licenses
The licenses section details the legal permissions and restrictions associated with the use of the COCO dataset. This includes copyright and user rights, ensuring users are informed about how the dataset can be legally utilized in their projects.
Understanding the licensing terms is essential for developers and companies aiming to incorporate COCO into commercial products or research. It helps in avoiding potential legal issues, promoting ethical use of the data while fostering innovation and development in the field.
For example: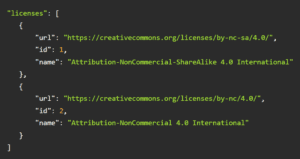
This JSON snippet indicates the legal terms under which images in the COCO dataset can be used. Each license is represented by an object within an array, detailing the license’s URL, its unique ID, and name. The URL points to the Creative Commons webpage that describes the full terms of the license.
Categories
The categories section outlines the different object classes included in the dataset, providing a framework for annotations. This categorization is important for training machine learning models, as it defines the scope of object recognition and segmentation tasks. Developers can tailor their algorithms to focus on specific object classes.
For example:
Each category object includes an ID, name, and supercategory (a higher-level classification).
Images
The images section is a collection of photographs captured in various settings. These images cover a wide range of scenes and objects for model training and testing. This diversity ensures that models developed using COCO can generalize across different visual contexts, enhancing their applicability in real-world scenarios.
For example:
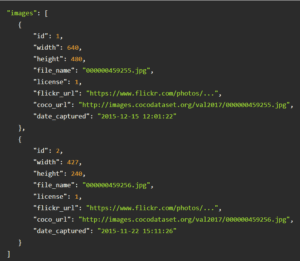
Annotations
The annotations section provides detailed information about objects present in the images, including their location, shape, and category. This includes bounding boxes, segmentation masks, and descriptive captions. These annotations are useful for tasks requiring precise object identification and contextual understanding, enabling accurate and context-aware models
For example:.

This JSON snippet includes the ID of the annotation, ID of its associated image, and the category ID indicating the type of object. The segmentation field contains coordinates for outlining the object, area specifies the size of the object within the image. bbox gives the bounding box coordinates, and iscrowd indicates if the annotation represents a single object or a group.
How to Use the COCO Dataset
The MS COCO dataset is provided under a Creative Commons Attribution 4.0 License, which grants users broad freedoms to distribute, modify, and use the dataset, including for commercial purposes, as long as the original creators are credited.
The COCO dataset is segmented into various subsets, each focusing on distinct computer vision tasks such as object detection, keypoint tracking, image captioning, and “stuff” detection. This allows users to focus on the parts of that dataset relevant to their research or application needs.
To access the dataset, download it using the gsutil rsync utility, a tool offered by Google Cloud for efficient file synchronization. To integrate and manipulate the dataset, use the COCO API. It is available in several programming languages, including Lua, MATLAB, and Python.
Testing and Evaluating Computer Vision Models with Kolena
We built Kolena to make robust and systematic ML testing easy and accessible for all organizations. With Kolena, machine learning engineers and data scientists can uncover hidden machine learning model behaviors, easily identify gaps in the test data coverage, and truly learn where and why a model is underperforming, all in minutes not weeks. Kolena’s AI / ML model testing and validation solution helps developers build safe, reliable, and fair systems by allowing companies to instantly stitch together razor-sharp test cases from their data sets, enabling them to scrutinize AI/ML models in the precise scenarios those models will be unleashed upon the real world. Kolena platform transforms the current nature of AI development from experimental into an engineering discipline that can be trusted and automated.
Among its many capabilities, Kolena also helps with feature importance evaluation, and allows auto-tagging features. It can also display the distribution of various features in your datasets.
Reach out to us to learn how the Kolena platform can help build a culture of AI quality for your team.


